
Wikipedia:Reference desk/Mathematics: Difference between revisions
edited by robot: archiving October 2 |
edited by robot: archiving October 3 |
||
| Line 1: | Line 1: | ||
[[Category:Non-talk pages that are automatically signed]]{{Wikipedia:Reference desk/header|WP:RD/MA}} |
[[Category:Non-talk pages that are automatically signed]]{{Wikipedia:Reference desk/header|WP:RD/MA}} |
||
| ⚫ | |||
{{Wikipedia:Reference_desk/Archives/Mathematics/2008 October 1}} |
{{Wikipedia:Reference_desk/Archives/Mathematics/2008 October 1}} |
||
| Line 7: | Line 5: | ||
{{Wikipedia:Reference_desk/Archives/Mathematics/2008 October 2}} |
{{Wikipedia:Reference_desk/Archives/Mathematics/2008 October 2}} |
||
| ⚫ | |||
= October 3 = |
|||
== Imaginary Numbers == |
|||
Hello. Does i<sup>4a</sup> = 1 because (i<sup>4</sup>)<sup>a</sup> = 1<sup>a</sup> = 1? There are no parameters onto which set of numbers ''a'' must belong. Is there any amibugity? Thanks in advance. --[[User:Mayfare|Mayfare]] ([[User talk:Mayfare|talk]]) 00:10, 3 October 2008 (UTC) |
|||
:1<sup>(3/2)</sup> = (e<sup>(2iπ)</sup>)<sup>(3/2)</sup> = -1 (just kidding ;), 1<sup>a</sup> = 1 for '''any''' a. [[User:Hydnjo|hydnjo]] [[User talk:Hydnjo|talk]] 02:16, 3 October 2008 (UTC) |
|||
:(e/c) i<sup>4a</sup>=1 only if a is an integer. Going from i<sup>4a</sup> to (i<sup>4</sup>)<sup>a</sup> does not follow order of operations. If a= 3/4, we get i<sup>4•3/4</sup>=i<sup>3</sup>=-i. [[User:Paragon12321|<span style="color:blue">Paragon</span>]][[User talk:Paragon12321|<span style="color:red"><sup>12321</sup></span>]] 02:53, 3 October 2008 (UTC) |
|||
::Parentheses matter. [[User:Hydnjo|hydnjo]] [[User talk:Hydnjo|talk]] 03:05, 3 October 2008 (UTC) |
|||
::This is another question where wikipedia ought really have a special article. I just had a look for a paradox based on it by [[Thomas Clausen (mathematician)]] because I was feeling evil, but I can even find it using google. [[User:Dmcq|Dmcq]] ([[User talk:Dmcq|talk]]) 09:19, 3 October 2008 (UTC) |
|||
::Actually, there's nothing wrong with i<sup>4•3/4</sup>=(i<sup>4</sup>)<sup>3/4</sup>=1<sup>3/4</sup>. You just have to remember that the complex exponential is multivalued, and you have to take the right value of the right-hand-side. The values of 1<sup>3/4</sup> are 1, -1, i and -i. [[User talk:Algebraist|Algebraist]] 09:23, 3 October 2008 (UTC) |
|||
::Hmm perhaps I'll just put in a version of that paradox by Clausen: |
|||
:::e<sup>2πin</sup> = 1 for all integer n |
|||
:::e<sup>1+2πin</sup> = e |
|||
:::(e<sup>1+2πin</sup>)<sup>1+2πin</sup> = e |
|||
:::e<sup>1+4πin-4π<sup>2</sup>n<sup>2</sup></sup> = e |
|||
:::e.e<sup>-4π<sup>2</sup>n<sup>2</sup></sup> = e |
|||
:::e<sup>-4π<sup>2</sup>n<sup>2</sup></sup> = 1 |
|||
::This is plainly false for any integer n except 0 but the original line was true for all integer n [[User:Dmcq|Dmcq]] ([[User talk:Dmcq|talk]]) 09:47, 3 October 2008 (UTC) |
|||
== Margin of error question...? == |
|||
If I ask a question to a simple random sample of 8 individuals out of a population of 40, and 1 out of these 8 say yes, then the percentage of yesses is 12.5% But how do I calculate the margin of error for, let's say, 90% confidence.? What formula could I plug all those numbers in?--[[User:Sonjaaa|Sonjaaa]] ([[User talk:Sonjaaa|talk]]) 14:59, 3 October 2008 (UTC) |
|||
:Statistics isn't my area, so I don't feel confident giving you a definite answer, but [[Sample size#Estimating proportions]] looks like the place to start. --[[User:Tango|Tango]] ([[User talk:Tango|talk]]) 15:28, 3 October 2008 (UTC) |
|||
The population size is <math> N= 40 </math> and the sample size is <math> n = 8 </math>. |
|||
The sample number of yeas is <math> i=1 </math> and the sample number of nays is <math> n-i=7 </math>. |
|||
The population number of yeas, <math> I </math>, assumes values from <math> (i =) </math> 1 to <math> (N-n+i =) </math> 33, and |
|||
the population number of nays, <math> N-I </math>, assumes values from <math> (n-i =) </math> 7 to <math> (N-i =)</math> 39. The number of ways to obtain <math> (N, n, I, i) </math> is the product of [[binomial coefficient]]s <math>\tbinom I i \tbinom{N-I}{n-i}=\tbinom I 1 \tbinom{40-I}{7}.</math> These 33 numbers are 15380937 25240512 30886416 33390720 33622600 32277696 29904336 26926848 23666175 20358000 17168580 14208480 11544390 9209200 7210500 5537664 4167669 3069792 2209320 1550400 1058148 700128 447304 274560 160875 89232 46332 22176 9570 3600 1116 256 33. Their sum is 350343565, which happens to be equal to <math>\tbinom {41} 9.</math> The general distribution function for <math> I </math> is actually <math>\tbinom I i \tbinom{N-I}{n-i}/\tbinom{N+1}{n+1}</math> but I am not going to prove it here. The accumulated values <math>\sum_{k=1}^I\tbinom k i \tbinom{N-k}{n-i}/\tbinom{N+1}{n+1}</math> are 0.04 0.12 0.2 0.3 0.4 0.49 0.57 0.65 0.72 0.78 0.82 0.86 0.9 0.92 0.94 0.96 0.97 0.98 0.99 0.99 0.99 1 1 1 1 1 1 1 1 1 1 1 1 for <math> I= </math> 1..33. So a 90% confidence interval is <math> 2\le I \le 15 </math> or <math> 5% \le I/N \le 37.5% </math>. [[User:Bo Jacoby|Bo Jacoby]] ([[User talk:Bo Jacoby|talk]]) 19:21, 4 October 2008 (UTC). |
|||
== Please help in German–English maths translation == |
|||
[[Borsuk's conjecture#Conjecture status]] waits for someone to verify a translation from German. --[[User:CiaPan|CiaPan]] ([[User talk:CiaPan|talk]]) 15:01, 3 October 2008 (UTC) |
|||
I can provide you the final English translation of that quotation on Saturday (tomorrow) if you answer my stats question above today... :) --[[User:Sonjaaa|Sonjaaa]] ([[User talk:Sonjaaa|talk]]) 15:21, 3 October 2008 (UTC) |
|||
:: I do not trade my skills here. And I really don't care what you can provide me, but would be glad if you can – and want to! – help to improve the article. <br/>Anyway I <big>'''[[hate]]'''</big> statistics. [<span title="This place intentionally left blank."> </span>] --[[User:CiaPan|CiaPan]] ([[User talk:CiaPan|talk]]) 06:26, 7 October 2008 (UTC) |
|||
== Grading on a Curve: Percents, Percentiles, and Z-Scores == |
|||
Let us say that there is a college class with 100 students, and this group is being co-taught by two professors. Philosophically, Professor X and Professor Y agree that ideal grade distributions are: 10% A, 20 % B, 40 % C, 20% D, and 10 % F. At the end of the year, each professor independently grades the class and this is how they grade. Professor X rank-orders the students' scores, high to low, from 1 to 100. Then, Professor X assigns an "A" grade to students ranked 1 through 10; a "B" grade to students ranked 11 through 30; a "C" grade to students ranked 31 through 70; a "D" grade to students ranked 71 through 90; and an "F" grade to students ranked 91 through 100. Professor Y approaches the task differently. Professor Y calculates a z-score for each student. A student whose z-score is at or above the 90th percentile (z = 1.28) earns an "A" grade. A student whose z-score is at or below the 10th percentile (z = -1.28) earns an "F" grade. And so forth with the appropriate z-score cut-offs for the "B" and "C" and "D" students. (To make the conversation easier, let us assume that there are no tie-scores and no tie-ranks at all.) Question 1: Will Professor X and Professor Y ultimately have the same final grades for the same students ... or will each method give different results? Question 2: If the results are different, why is that exactly? Question 3: If the class scores are (or are not) normally distributed, does that make any difference or not? Thanks. ([[User:Joseph A. Spadaro|Joseph A. Spadaro]] ([[User talk:Joseph A. Spadaro|talk]]) 16:58, 3 October 2008 (UTC)) |
|||
:It all depends on the distribution of marks. Consider the case where 1 student gets 100%, 1 gets 99.99%, 1 gets 99.98% and so on for the first 50 down to 99.51% and the other 50 have a similar distribution in the range 0% to 0.49%. Prof X will get the ideal grade distributions, but Prof Y will get half B's and half D's (if I've calculated it correctly). The difference is because Prof X forces the grades to be exactly the ideal distribution whereas Prof Y calculates the grades based on individual marks and weights it so that the ''expected'' distribution for a normally distributed set of marks will be the ideal distribution. The actual grades will depend on the actual marks, just because a variable is normally distributed doesn't mean a sample will follow that distribution exactly (or even at all for a small sample). I would say Prof Y has the better method, since how good a student you are doesn't actually depend on how good your peers are - some years are just cleverer than other years due to all kinds of influences (including random fluctuation). As long as you try and keep the exam difficulty the same from year to year (not always easy, admittedly), then you'll get fair grades. --[[User:Tango|Tango]] ([[User talk:Tango|talk]]) 00:11, 4 October 2008 (UTC) |
|||
:: Thank you. Three follow-ups to your above comment. (1) If indeed the particular scores of this class were normally distributed, then Professor X's method and Professor Y's method will and should yield the exact same results ... is that correct? (2) To paraphrase, are you saying something along the lines of the following? Professor Y is basing his system on an idealized (normal) distribution, and then superimposing his actual student performance over that theoretical student performance (normal distribution). Professor X is artificially assuming that his group is indeed ideal (normal), whether they are or not. Is that what you are in essence saying? (3) You make the statement that: "Prof Y has the better method, since how good a student you are doesn't actually depend on how good your peers are." Under Professor Y's system, your entire grade (via your z-score) is indeed based on the performance of your peers, no? That is the very definition of your z-score ... comparing you with those being evaluated along with you. A student's z-score derives from the overall class mean and standard deviation. And thus, how well I do (via my z-score) is indeed contingent upon my comparison to my peers and how well they do. Is that not correct? Thanks. ([[User:Joseph A. Spadaro|Joseph A. Spadaro]] ([[User talk:Joseph A. Spadaro|talk]]) 01:19, 4 October 2008 (UTC)) |
|||
:::1) Yes, I think so (to the extent that it makes sense to say that a sample is normally distributed - I think it's better to say that it's representative of a normal distribution, although that may just be me). 2) Not really, Prof X's method doesn't involve a normal distribution in any way. 3) Yes, good point. It does depend on your peers, but only via the class performance as a whole rather than individual peers, which is why it is better. It would be better still to calculate the z-scores compared to the last few years data which would account for differences between cohorts (although it requires consistent exams, which can be hard to achieve, especially if the syllabus changes). --[[User:Tango|Tango]] ([[User talk:Tango|talk]]) 12:17, 4 October 2008 (UTC) |
|||
:Re (2). No, professor X is making no assumption whether the distribution is a [[normal distribution]] or not. He simply forces the 'ideal grade distribution' to be true each year, without regard to whether the students this year are better or worse than the students last year. If the answers and grades from two years are compared, the results may be unfair. The ambitious student selects a class of stupid peers in order to obtain a high grade. Basicly, both professors are cheeting. The grade should reflect the competence of the student, and not that of his peers. [[User:Bo Jacoby|Bo Jacoby]] ([[User talk:Bo Jacoby|talk]]) 04:38, 4 October 2008 (UTC). |
|||
::An interesting case of normalizing scores happens with setting up [[IQ]] tests where the normalization involves ranking the scores for a test sample of people and projecting them onto a normal distribution. So the z-score will be exactly the same for that sample. The distribution of types of questions can also be altered so different groups of people get the same average - this is to avoid bias! [[User:Dmcq|Dmcq]] ([[User talk:Dmcq|talk]]) 12:23, 4 October 2008 (UTC) |
|||
:::That's too what I was trying to avoid thinking about. IQ tests are done like that also. They grade people like prof Y. For example, the IQ test which I'm studying and have trouble accepting, is vulnerable to the scenario mentioned. It would be possible for the clusters of scores to skew the Z-scores in a way that makes no intuitive sense. [[User:Sentriclecub|Sentriclecub]] ([[User talk:Sentriclecub|talk]]) 13:18, 4 October 2008 (UTC) |
|||
::::For an IQ test to work they need to use a large enough sample for the normalisation so that the risk of clusters like that is minimal. The IQ reported is basically a z-score, just expressed in a different way (z-scores are arranged so the mean is 0 and the standard deviation is 1, for an IQ the mean is 100 and the standard deviation is fixed, although what's it's fixed to varies from test to test). --[[User:Tango|Tango]] ([[User talk:Tango|talk]]) 15:19, 4 October 2008 (UTC) |
|||
=== Follow up === |
|||
Thanks to all for the above comments. Here is my follow-up question. In the world of education (specifically, higher education) ... or even in the world of math / statistics / testing / evaluation / etc. ... is there any accepted "standard" of grade distribution? In the above example, I simply (and conveniently) "made up" the distribution of 10%-20%-40%-20%-10% for the A-B-C-D-F grade ranges. Are there any statistically sound or generally accepted distributions? Thanks. ([[User:Joseph A. Spadaro|Joseph A. Spadaro]] ([[User talk:Joseph A. Spadaro|talk]]) 14:46, 4 October 2008 (UTC)) |
|||
:Not really. See [[grade inflation]] for one thing that stops such a distribution from existing. --[[User:Tango|Tango]] ([[User talk:Tango|talk]]) 15:19, 4 October 2008 (UTC) |
|||
:If you want a mathematically justified choice of grade distribution, you could choose a uniform distribution (i.e., 20%-20%-20%-20%-20%). This choice of distribution maximizes the [[entropy (information theory)|information]] conveyed by a single grade. However, this choice ignores the non-mathematical issues which dominate the choice of a grade distribution. Eric. [[Special:Contributions/131.215.159.210|131.215.159.210]] ([[User talk:131.215.159.210|talk]]) 10:20, 5 October 2008 (UTC) |
|||
:: I guess that I would like to know ... what percent of a distribution would (statistically) be considered "exceptional", what percent would be considered "above average", "average", "below average", etc. Alas ... it is probably circular. The grade of A ("exceptional") means whatever X% the professor considers to be exceptional. Just wondered if there were any standards across fields of statistics / testing / psychology / measurements & evaluation / etc. Thanks. ([[User:Joseph A. Spadaro|Joseph A. Spadaro]] ([[User talk:Joseph A. Spadaro|talk]]) 21:47, 5 October 2008 (UTC)) |
|||
:::I don't think there is a standard definition. You may fine [[outlier]] interesting, it gives some of the definitions people use. --[[User:Tango|Tango]] ([[User talk:Tango|talk]]) 12:58, 6 October 2008 (UTC) |
|||
:::: Thanks. I will look at that article. ([[User:Joseph A. Spadaro|Joseph A. Spadaro]] ([[User talk:Joseph A. Spadaro|talk]]) 14:57, 6 October 2008 (UTC)) |
|||
: My impression, based on a few years of teaching nights at a local college, is that there is a three part distribution; the A students identify themselves and so do the F students; the B-C-D folks might follow a Gaussian distribution. [[User:Gzuckier|Gzuckier]] ([[User talk:Gzuckier|talk]]) 15:40, 6 October 2008 (UTC) |
|||
Thanks to all for your input on my question. Much appreciated. ([[User:Joseph A. Spadaro|Joseph A. Spadaro]] ([[User talk:Joseph A. Spadaro|talk]]) 01:10, 7 October 2008 (UTC)) |
|||
= October 4 = |
= October 4 = |
||
Revision as of 02:35, 8 October 2008
![]()
of the Wikipedia reference desk.
Main page: Help searching Wikipedia
How can I get my question answered?
- Select the section of the desk that best fits the general topic of your question (see the navigation column to the right).
- Post your question to only one section, providing a short header that gives the topic of your question.
- Type '~~~~' (that is, four tilde characters) at the end – this signs and dates your contribution so we know who wrote what and when.
- Don't post personal contact information – it will be removed. Any answers will be provided here.
- Please be as specific as possible, and include all relevant context – the usefulness of answers may depend on the context.
- Note:
- We don't answer (and may remove) questions that require medical diagnosis or legal advice.
- We don't answer requests for opinions, predictions or debate.
- We don't do your homework for you, though we'll help you past the stuck point.
- We don't conduct original research or provide a free source of ideas, but we'll help you find information you need.
How do I answer a question?
Main page: Wikipedia:Reference desk/Guidelines
- The best answers address the question directly, and back up facts with wikilinks and links to sources. Do not edit others' comments and do not give any medical or legal advice.
October 1
Recurrence
Can someone please explain this to me: I have the Ramsey function . I want to show that . My book says that use a certain binomial coefficient. Can someone help? Thanks--Shahab (talk) 07:44, 1 October 2008 (UTC)


- Oh never mind. Pascal's identity was what I was looking for. The proof was by double induction.--Shahab (talk) 08:11, 1 October 2008 (UTC)
algebra
They gave me this equation to use and I was ookay with it for a while. x = a1 b1 + a2 b2 / a1 + a2 but now they expect me to find b2!
I know I should bring it around so that the one side is x/a1 b1 + a2
But what do I do with a1 + a2? Do I put it so that x + (a1 + a2) or should I do it like x(a1 + a2)? --Jeevies (talk) 15:24, 1 October 2008 (UTC)
- Step by step, apply the same operation to both sides. Adding parentheses and operators as my assumption of what you mean with your equation we have
x = ( ( ( a1 * b1 ) + ( a2 * b2 ) ) / a1 ) + a2.
Thus your first step would transform to the equation
( x - a2 ) = ( ( ( a1 * b1 ) + ( a2 * b2 ) ) / a1 ) + a2 - a2 = ( ( ( a1 * b1 ) + ( a2 * b2 ) ) / a1 ).
Carry on from there. -- SGBailey (talk) 15:39, 1 October 2008 (UTC)
October 2
While I understood long ago that .999... = 1, I was wanting to ask a question that is implicatively the inverse of the .999... theorem: is 0.000...{infinity}...001 = 0? As an aside, I realise this question is quite trivial and simple; I ask only as a matter of interest, and extend thanks to anyone kind enough to offer me an answer. :) —Anonymous DissidentTalk 03:36, 2 October 2008 (UTC)
- I don't see how 0.000...{infinity}...001 is a meaningful expression. If it is has infinite zeros then it can't terminate in a one. Dragons flight (talk) 03:47, 2 October 2008 (UTC)
- Language peeve alert -- please, I think you mean infinitely many zeroes, not that there are zeroes that are individually infinite.
- On the content -- it depends on what you mean by "meaningful". There is nothing wrong, syntactically, with having an infinite string of zeroes (this time infinite as an adjective is fine, since it modifies string rather than zeroes), then followed by a one. However this string is not the decimal representation of any real number. --Trovatore (talk) 03:53, 2 October 2008 (UTC)
- I understand it is not real; I just was wondering if infinity could be confined in any sort of way so that we could have something on the other side. While ∞+1makes no sense, my real question was whether we could have an (∞) and then something else on the other side, in a decimal context. —Anonymous DissidentTalk 04:05, 2 October 2008 (UTC)
- Sure, why not? But it's just a string of symbols (albeit an infinitely large string). It's not a decimal representation. It doesn't denote anything (at least, not in any standard way). --Trovatore (talk) 04:12, 2 October 2008 (UTC)
- No, it's worse than that. It suggests you should construct a string of symbols that could never be written down, is logically impossible, and can't be connected to the normal meaning of such symbols. It's like saying "write the 32nd letter of the English alphabet". It's not even false, because what it attempts to refer to is non-existent. In short it's mathematical gibberish. Dragons flight (talk) 04:23, 2 October 2008 (UTC)
- Can't write down? But you can't write down, say, a string of a quintillion symbols, either. That doesn't prevent us from studying such strings.
- Logically impossible? Please provide a proof of a statement and its negation, from the assumption that such a string of symbols exists, using logic alone (that is, you are not allowed any other assumptions whatsoever). Logical impossibility is an extremely strong condition.
- There is nothing wrong whatsoever with infinite strings of symbols. They give you a good way to think about (for example) the Cantor space and the Baire space. A very nice elementary example from the theory of Borel equivalence relations is doubly-infinite words on some finite alphabet, where you forget where the origin is. None of this is "mathematical gibberish"; it's actually excellent mathematics. --Trovatore (talk) 04:37, 2 October 2008 (UTC)
- One can add definitions to mathematics, and create a system where that symbol might refer to something, but that's the same as saying I can define the 32 letter in English to be "
 ". Yes, there are many contexts where infinite sequences exist and are useful. But can you give any examples where the infinite sequences are terminated by a finite number of elements? To say an infinite sequence is terminated is a logically impossibility for any normal definition of "infinite sequence" and "terminated". The above notation doesn't make sense within the normal framework of decimal notation, and trying to bootstrap meaning onto a post-infinite notation simply to respond to Anonymous Dissident is bad mathematics. Dragons flight (talk) 05:49, 2 October 2008 (UTC)
". Yes, there are many contexts where infinite sequences exist and are useful. But can you give any examples where the infinite sequences are terminated by a finite number of elements? To say an infinite sequence is terminated is a logically impossibility for any normal definition of "infinite sequence" and "terminated". The above notation doesn't make sense within the normal framework of decimal notation, and trying to bootstrap meaning onto a post-infinite notation simply to respond to Anonymous Dissident is bad mathematics. Dragons flight (talk) 05:49, 2 October 2008 (UTC)
- Believe it or not we do this (put something at the end of an infinite sequence) all the time. You should look at the articles ordinal number and transfinite induction. I see you have an undergrad degree in math but unless you took a course specifically in math logic you likely didn't get to these. In first-year graduate real analysis you'd likely have run across them in passing, say in the construction of the Borel hierarchy.
- Now, as for it not making sense in the "normal framework of decimal notation", I said as much. I said that this infinitely long symbol doesn't, in any ordinary way, denote anything. But this is a separate issue from whether it makes sense to have an infinite sequence with something at the end -- it most definitely does make sense and is not bad mathematics. --Trovatore (talk) 07:17, 2 October 2008 (UTC)
- You can write the .00000.....1 as (0,1) instead and then you'll find it all works out quite nicely as in nonstandard arithmetic, plus it's shorter to write. That article could do with a bit of expansion. Dmcq (talk) 07:46, 2 October 2008 (UTC)
- Um, this one is not clear to me; I'm not sure what your notation means. What I was telling Anonymous Dissident was that you could make the string of symbols, not that there was any natural arithmetic to do with those strings. If you're talking about nonstandard models of arithmetic (and/or analysis) that's another kettle of fish—the positions in the decimal expansions of "reals" in the sense of those models are themselves nonstandard naturals, and some care has to be taken to make sense of it all. --Trovatore (talk) 09:34, 2 October 2008 (UTC)
- You can write the .00000.....1 as (0,1) instead and then you'll find it all works out quite nicely as in nonstandard arithmetic, plus it's shorter to write. That article could do with a bit of expansion. Dmcq (talk) 07:46, 2 October 2008 (UTC)
- One can add definitions to mathematics, and create a system where that symbol might refer to something, but that's the same as saying I can define the 32 letter in English to be "
- No, it's worse than that. It suggests you should construct a string of symbols that could never be written down, is logically impossible, and can't be connected to the normal meaning of such symbols. It's like saying "write the 32nd letter of the English alphabet". It's not even false, because what it attempts to refer to is non-existent. In short it's mathematical gibberish. Dragons flight (talk) 04:23, 2 October 2008 (UTC)
- Sure, why not? But it's just a string of symbols (albeit an infinitely large string). It's not a decimal representation. It doesn't denote anything (at least, not in any standard way). --Trovatore (talk) 04:12, 2 October 2008 (UTC)
- I understand it is not real; I just was wondering if infinity could be confined in any sort of way so that we could have something on the other side. While ∞+1makes no sense, my real question was whether we could have an (∞) and then something else on the other side, in a decimal context. —Anonymous DissidentTalk 04:05, 2 October 2008 (UTC)
- Dragons flight asked: 'can you give any examples where the infinite sequences are terminated by a finite number of elements?'
Please see the Sharkovskii's theorem, which gives an example of such infinite chain, that has a known infinite sequence as its beginning, a known infinite sequence as a tail, an infinite number of infinite sub-sequences inside itself and exhausts positive integers putting them in a total order. --CiaPan (talk) 12:29, 2 October 2008 (UTC)
- Dragons flight asked: 'can you give any examples where the infinite sequences are terminated by a finite number of elements?'
- Have you already read the article on 0.999...? While it doesn't actually use the 0.000...01 notation, the section on "Alternative number systems" covers some of the ideas of what you have to break in the real numbers to let you have a non-zero value equal to 1 - 0.999... The talk page and associated arguments page (linked from talk) go a little more into it, and the fact is that you can break out transfinite numbers or surreal numbers or something to extend decimal expansions, but you can't then just assume that they'll work like normal decimals, and you have to determine a new set of rules for working with them. Since the decimal system is designed to represent real numbers, something's gotta give. Confusing Manifestation(Say hi!) 04:17, 2 October 2008 (UTC)
- Thanks very much for that pointer to 0.999.... The bit about alternative number systems says all I wanted to say about infinitesimal calculus and I was just thinking of looking for that bit of game theory with Hackenbush where the value of one position can be greater than that of another but not by any finite amount. The introduction is good, I suppose it's okay to be dogmatic about .999 being 1 and erroneous intuitions about infinitesimals even if that really depends on using standard real numbers as defined using Dedekind cuts or suchlike. Dmcq (talk) 22:10, 2 October 2008 (UTC)
Infinite sequences with something after them
OK, this is not strictly in the spirit of the refdesk, but I'd really like to say something about this strange meme that nothing can follow an infinite sequence, or that you can't do infinitely many things and then do something else. You see this in lots of otherwise mathematically well-informed folks, and it has a pernicious effect on their mathematical reasoning, sometimes leading them away from the most natural arguments.
Take as an example the Cantor-Bendixson theorem, which says that if you have a closed set of real numbers (or closed set in some other Polish space), then you can remove countably many points and have remaining a (possibly empty) perfect set; that is, a closed set with no isolated points. What's the natural way to show this? Well, delete all the isolated points, of course (easy to see there can be only countably many such).
Unfortunately, some points that were not isolated before may have become isolated, because you've removed a sequence of points that accumulated to them. So you remove these new isolated points as well. And you keep going, if necessary.
Now, after infinitely many iterations (that is, taking the intersection of everything you got at a finite iteration), do you still have isolated points? Possibly. You could have removed one point at stage 0, another at stage 1, another at stage 2, and so on, and these accumulated to some point that becomes isolated only at this first infinite stage. No problem; we keep on going beyond that.
There are a few details to check, but it's a fact that this process must close off at some countable ordinal number. At each stage you've removed only countably many points, and the countable union of countable sets is countable, so you're done, proof complete.
This is by far the most natural and perspicacious proof of the theorem. But lots of mathematicians, perversely, prefer an all-at-once proof involving looking at the set of condensation points. of the original set. Their proof, I will concede, is not really harder. But it's much less enlightening. The only reason I can see to prefer it is if you're not comfortable with transfinite induction. But there's no excuse not to be comfortable with transfinite induction! It's an absolutely basic technique and every mathematician needs to know it. I think that this unfortunate notion that nothing can follow infinitely many things may be at the root of their discomfort. --Trovatore (talk) 19:42, 3 October 2008 (UTC)
- Interesting. But I'm not convinced the prejudice against your proof has anything to do with transfinite induction. Here's a similar example that doesn't even reach ω:
- Problem: Given n "red" points and n "blue" points, a "pairing" of the points is a set of n line segments with one red and one blue endpoint, different for each segment. Show that any set of n red and n blue points on the plane in general position has a pairing with no intersections.
- Proof 1: Start with any pairing and uncross intersecting segments (by swapping which blue point corresponds to which red) until you can't any more. This process must terminate because each uncrossing operation decreases the total length of the segments, by the triangle inequality, and there are only finitely many possible pairings.
- Proof 2: Pick a pairing of minimum total length. It can't contain any intersections because you could then get a shorter pairing by uncrossing them.
- Problem: Given n "red" points and n "blue" points, a "pairing" of the points is a set of n line segments with one red and one blue endpoint, different for each segment. Show that any set of n red and n blue points on the plane in general position has a pairing with no intersections.
- I find the first proof more intuitive, but the mathematician in me prefers the second one. I think the prejudice in your problem and mine is against proofs that invoke time and change. The answer to the problem is there in the Platonic realm, so better (the thinking goes) to grab it directly than to muck around with other objects that don't answer the question. -- BenRG (talk) 08:29, 4 October 2008 (UTC)
- But an argument in favour of Proof 1 is that it is more general because it depends only on the topological properties of the underlying space, whereas Proof 2 assumes that the underlying space is a metric space. So Proof 1 can be generalised to cases where the connections between the points are not necessarily line segments (and maybe there is not even a definition of "straight line" in the space), whereas Proof 2 cannot be so generalised. Gandalf61 (talk) 09:52, 4 October 2008 (UTC)
So Ben, I don't really think your example is quite analogous. Your two proofs are close enough that I would call them the "same" proof; the inductive procedure in proof 1 is limited to showing that every finite partial order has a minimal element, which the second proof simply takes for granted. Other than that the two proofs are identical, unless I've missed something.
In my example, on the other hand, it's trivial to see that there's a subset of the original set that's left unchanged by one iteration; it's the empty set. But that doesn't help, because what we want to know is that we have to delete only countably many points. The all-at-once proof does have the merit of characterizing the points that are kept, but the inductive proof shows the structure of what has to be removed (and in particular the structure of countable closed sets in general).
Another class of examples of my point is the way that algebra classes, following Bourbaki, bundle all uses of the axiom of choice into the clunky and intuitively obscure Zorn's lemma, applications of which can almost always be replaced by a simple and clear transfinite induction in which you make a choice at each step. --Trovatore (talk) 19:12, 4 October 2008 (UTC)
Logic problem: Working out Wendy's birthdate
I wrote an article on Wendy Whiteley the other day, and later I started looking at what little evidence I've mustered, in order to narrow down when she was born.
I thought I'd got it to between 7 April and mid-October 1941, but when I added in the known age (17) of her future husband Brett Whiteley when they first met, and knowing exactly when he was born (7 April 1939), I was led to conclude she must have been born before 7 April 1941. It can't have been both before and after 7 April 1941. The possibility that they had the same birthday (7 April), exists, but I'm sure that coincidence would have been mentioned many times in the literature, and I've never seen any such references.
Can some kind soul take a glance over my thinking at Talk:Wendy Whiteley and tell me what logical errors I've made or what wrong assumptions I've assumed. Or, maybe I've made no logical errors, but the evidence is inherently contradictory and my analysis has simply revealed this to be the case. I'm pretty sure everything you need to know is there, but if not, just ask.
Thanks for any assistance you can provide. -- JackofOz (talk) 03:55, 2 October 2008 (UTC)
- Bear in mind that being a "round number", 'now 65' might mean 'now over 65' and thus anything from 65.0 to 69.9 -- SGBailey (talk) 07:57, 2 October 2008 (UTC)
- That's possible, but I think unlikely. The full sentence is "Standing on the balcony of the Whiteley house, gazing out at the water through the sinuous Moreton Bay fig and three cabbage tree palms that Brett so often depicted in his harbour paintings, Wendy, now 65, is, as ever, an eye-catching walking work of art herself". If she was really 67 at the time, this would be a very misleading statement. -- JackofOz (talk) 19:58, 2 October 2008 (UTC)
Continuity on the complex plane
Hi. I'm in a complex variables class, and I'm struggling with a homework problem. I'd like a hint, or a push in the right direction.
We're given that D is the domain obtained by removing the interval of the real line from the complex plane. We want to show that a branch of the cube root function on this domain is given by:

![{\displaystyle g(z)={\begin{cases}{\sqrt[{3}]{z}}&{\mbox{if }}Re(z)\geq 0\\{\frac {-1+i{\sqrt {3}}}{2}}{\sqrt[{3}]{z}}&{\mbox{if }}Re(z)<0\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e0096c42d41edf61e61571925cd02c3ab058827b)
To be a branch of an inverse function, g(z) must be a right inverse of f(z) (where f(z)=z3), and it must be continuous. Showing that it's a right inverse is no problem, but the continuity is giving me trouble. My instinct tells me that, when choosing , I'll want to make it a minimum of two options, one for the line near the origin, and another for the rest of the line. I'm also pretty confident that I want to start out with:

![{\displaystyle |{\sqrt[{3}]{z}}-{\sqrt[{3}]{z_{0}}}|={\frac {|z-z_{0}|}{|z^{2/3}+z^{1/3}z_{0}^{1/3}+z_{0}^{2/3}|}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/91a60ddc03aed4648895c96c71fecdcfa7d0b8dd)
...and then I want to bound that denominator from below, but I'm stuck right there. Can someone please throw me a bone? -GTBacchus(talk) 15:56, 2 October 2008 (UTC)
- The equation x3=z has 3 complex solutions, each of which can be called a 'cube root of z'. So your function g(z) is not really well defined. If x is one of the solutions, the other two are xa and xa2 where a=e2πi/3 is a primitive cube root of unity, (a≠1, a2≠1, a3=1). Assume that z moves continuously around the unit circle from 1 to 1. (z=eiφ, 0<φ<2π), then the root x=eiφ/3 moves continuously from 1 to a, and the root xa moves continuously from a to a2, and the root xa2 moves continuously from a2 to 1. I hope this is helpful to your understanding. Bo Jacoby (talk) 20:12, 2 October 2008 (UTC).
- I probably should have said that, in the notation we've been using, is defined as , where the first factor is a real number and where denotes the principal argument of z, which is always in the interval . In other words, denotes the principal cube root of z, which satisfies . With that clarification, the function is well-defined, and I still don't know how to show that it's continuous along the negative real axis.
Thanks for pointing out the ambiguity in my notation, though. -GTBacchus(talk) 22:11, 2 October 2008 (UTC)
- I probably should have said that, in the notation we've been using, is defined as , where the first factor is a real number and where denotes the principal argument of z, which is always in the interval . In other words, denotes the principal cube root of z, which satisfies . With that clarification, the function is well-defined, and I still don't know how to show that it's continuous along the negative real axis.
![{\displaystyle {\sqrt[{3}]{z}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/27f2f0f796cf622e8d14e33cb7754a127742271b)
![{\displaystyle {\sqrt[{3}]{|z|}}\cdot e^{\frac {Arg(z)}{3}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4a667e854d294fb7970874800a95bffed0c62a33)

![{\displaystyle (-\pi ,\pi ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7fbb1843079a9df3d3bbcce3249bb2599790de9c)
![{\displaystyle -{\frac {\pi }{3}}<Arg\left({\sqrt[{3}]{z}}\right)\leq {\frac {\pi }{3}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/da811470cf55198baa30b8bb42ca7aa76dfbb8cc)

- Consider a small positive angle ε.
- while
- so the principal cube root is not continuous at −1. Bo Jacoby (talk) 10:39, 3 October 2008 (UTC).
- I know the principal cube root is discontinuous at -1; the point of this problem is to define a different branch, g(z), that is continuous at -1, and which is discontinuous at 1. The function g(z) is not the principal cube root; it's the notation that is taken to mean the principal cube root. That's how the function is well-defined, because we're not using "" to mean just any old cube root. As you can see, g(z) is different from that in the bottom half-plane. It's different by an argument of 2π/3. -GTBacchus(talk) 20:38, 4 October 2008 (UTC)
- Indeed. As given, g is discontinuous along the negative axis. Moreover, it cannot be fixed by changing only the second clause of the definition: principal is continuous along the positive real axis, hence if such a variant of g were continuous, it would have a holomorphic extension to all of , which is impossible. — Emil J. 11:15, 3 October 2008 (UTC)
- Ok, apparently I'm not communicating this clearly at all. This problem comes straight out of the textbook, and I don't think it's a misprint.
I am quite well aware that the principal cube root is continuous on the positive real axis, and discontinuous on the negative real axis. This problem is about defining a different cube root function - not the principal cube root - that is continuous on the negative real axis, and discontinuous on the positive real axis. Nobody is trying to define a cube root that's holomorphic on ; I agree that's impossible. What we're doing is moving the discontinuity to the positive side, which is not impossible.
The function g(z), given above, is very, very discontinuous on the positive real axis, and it's very, very continuous on the negative real axis. Just think about plugging in a number whose principal argument is just short of π - the function g will return a number just short of π/3. Now plug in a number just below the negative real axis, so its principal argument is very close to -π. The function g, as given, will return a value slightly greater than -π/3, multiplied by , which puts us just past π/3.
The function g, as given, is equal to the principal cube root only in the top half-plane, and it's equal to a different cube root in the bottom half-plane, one chosen so that it will be continuous on the negative real axis, and the discontinuity is moved to the positive real axis. The range of g(z) is the segment of the complex plane with principal argument ranging from 0 to . It's not impossible; in fact, this is a quite standard problem in defining different branches of inverse functions. What I really want is some help with the epsilon-delta argument. Can anyone help me with that, or do I have to settle for people telling me that my textbook, my professor, and my clear understanding are wrong, and that g(z) is either not well-defined, or is the principal cube root, when I know damn well that it isn't? This is frustrating. Can someone who understands branches of inverse functions please help me with the epsilons and deltas? -GTBacchus(talk) 20:38, 4 October 2008 (UTC)
- I haven't read all this discussion, but I think that in your original definition of g, you wanted to split the definition according to the sign of the imaginary part of z, not the real part. Algebraist 22:19, 4 October 2008 (UTC)
- Holy cow; you're right. That's precisely what I meant to do. Now I feel stupid, and I'd really like to know how to prove continuity on the negative real line for the function defined:
- I apologize for screwing up so royally. Now I know why this discussion has been so incredibly frustrating. If anyone can look past my stupidity and help me, I would be very, very grateful. -GTBacchus(talk) 00:34, 5 October 2008 (UTC)
- Holy cow; you're right. That's precisely what I meant to do. Now I feel stupid, and I'd really like to know how to prove continuity on the negative real line for the function defined:
- I haven't read all this discussion, but I think that in your original definition of g, you wanted to split the definition according to the sign of the imaginary part of z, not the real part. Algebraist 22:19, 4 October 2008 (UTC)
- Ok, apparently I'm not communicating this clearly at all. This problem comes straight out of the textbook, and I don't think it's a misprint.
- Just show that for positive a. And don't call yourself stupid. Errare humanum est. Bo Jacoby (talk) 08:15, 5 October 2008 (UTC).
- That would only show that the limit is the same coming from two directions; to show continuity, we must show that it is the same from any direction. In particular, I have to show that, for every on the negative real line, and given any small , there is some so that, whenever , we have . There are examples of complex functions with limits existing when a point is approached in two, four, or any number of directions, which still fail to be continuous. I know that there is an argument beginning in the manner I suggested in my original post, and I'd very much like to find it.
I'm not stupid, but I did something stupid, and then compounded it by failing to re-read my original post and discover the error. Don't worry about my self-esteem; I know that I'm quite bright, but I've also got stupidity in me. Similarly, I'm generous, but I've got greed in me; I'm modest, but I've got pride in me; I'm patient and thoughtful, but I've got impetuousness in me. I'm okay with all of that. Thanks though, for reminding me that I'm allowed my errors. -GTBacchus(talk) 22:31, 5 October 2008 (UTC)
- That would only show that the limit is the same coming from two directions; to show continuity, we must show that it is the same from any direction. In particular, I have to show that, for every on the negative real line, and given any small , there is some so that, whenever , we have . There are examples of complex functions with limits existing when a point is approached in two, four, or any number of directions, which still fail to be continuous. I know that there is an argument beginning in the manner I suggested in my original post, and I'd very much like to find it.
- You are perfectly right. But take one step at a time. The g-function is composed of functions that are continuous except at the real axis. That proves continuity except at the real axis. The second step is the one above. The third step is to release the constraint that ε is a positive real. (For variable z and fixed z0≠0 consider z/z0−1). The fourth step is the case z0=0. Making mistakes is an unavoidable and actually desirable component of the process of learning. If you are less stupid today than yesterday, then you have learned something. Bo Jacoby (talk) 07:25, 6 October 2008 (UTC).
- Wow, this is very frustrating. I feel as if I'm being talked down to. Please drop the condescending tone. I don't feel bad about making mistakes, nor do I need reassurance about the learning process. I've been teaching mathematics for about 15 years, and learning it for about twice that long. I've made thousands and thousands of mistakes, and I'm grateful for every one of them. The mistake in this case was a fucking stupid typo (though I'm not stupid), and then a failure to scroll up and read what I'd typed. I'm grateful for that stupid mistake; thank you. (And no, I don't use words like "stupid" except when I'm among colleagues who know that we're all qualified and not really stupid. I thought this was such a context - it has been before.)(Insertion: I am sorry. I had no intention of talking down to anybody. Bo Jacoby (talk) 12:27, 7 October 2008 (UTC).)
I know that we've got continuity except on the negative real line - "step one" was done before I ever posted here. The "second step" you indicated is easy. I can do it in my sleep: When , there's nothing to do; just let go to 0. When , then we have: , and again we can just let go to 0. Ok?
That's easy because we're only comparing z0 with other numbers that have the same modulus. If I write up what I just did, my professor will ask why I'm screwing around with the easy case instead of just going straight to the general one. What you're calling "step 3" makes your "step 2" redundant and unnecessary. It's a good exercise for beginners, but this is a graduate level course. You're right that is a separate case, and I've not asked for help with that one; all I need there is to take . because the cube root is a strictly increasing function on the positive reals. That's a piece of cake.
Sigh.
Your hint about looking at may work. I don't yet see how it will give me a string of inequalities beginning with and ending with , but I'll work on that. Thank you for that hint. It's already too late to turn this in, but I'm going to work out the details anyway, for my own learning. Thanks again - I mean that. I am irritated with this interaction on other levels, but I do appreciate the math help.
I've used this resource in the past without feeling that I've been treated like a child; I'm not sure what went wrong this time. If I ask for help here in the future, I'll try to more clearly indicate my level of understanding, so I don't get handed Continuity 101 and the "it's ok to make mistakes" lecture. I hope you can understand what I find exasperating about this exchange. -GTBacchus(talk) 15:50, 6 October 2008 (UTC)
- Wow, this is very frustrating. I feel as if I'm being talked down to. Please drop the condescending tone. I don't feel bad about making mistakes, nor do I need reassurance about the learning process. I've been teaching mathematics for about 15 years, and learning it for about twice that long. I've made thousands and thousands of mistakes, and I'm grateful for every one of them. The mistake in this case was a fucking stupid typo (though I'm not stupid), and then a failure to scroll up and read what I'd typed. I'm grateful for that stupid mistake; thank you. (And no, I don't use words like "stupid" except when I'm among colleagues who know that we're all qualified and not really stupid. I thought this was such a context - it has been before.)(Insertion: I am sorry. I had no intention of talking down to anybody. Bo Jacoby (talk) 12:27, 7 October 2008 (UTC).)
![{\displaystyle \lim _{\epsilon \rightarrow 0^{+}}{\sqrt[{3}]{-e^{i\epsilon }}}=\lim _{\epsilon \rightarrow 0^{+}}e^{\epsilon -\pi i \over 3}=e^{-\pi i \over 3}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7f989f7980b1992b919973a53c4685a7384e65ee)
![{\displaystyle {\sqrt[{3}]{\lim _{\epsilon \rightarrow 0^{+}}-e^{i\epsilon }}}={\sqrt[{3}]{-1}}=e^{+\pi i \over 3}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2587b9a50d0aa0cf342d887b01e5b5e4e0b1c809)



![{\displaystyle g(z)={\begin{cases}{\sqrt[{3}]{z}}&{\mbox{if }}Im(z)\geq 0\\{\frac {-1+i{\sqrt {3}}}{2}}{\sqrt[{3}]{z}}&{\mbox{if }}Im(z)<0\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4b2f8bd075e12714dd745ac662e8c9ebed9e04b2)







![{\displaystyle g(z_{0}e^{i\epsilon })={\sqrt[{3}]{z_{0}e^{i\epsilon }}}{\frac {-1+i{\sqrt {3}}}{2}}={\sqrt[{3}]{|z_{0}|e^{i(-\pi +\epsilon )}}}{\frac {-1+i{\sqrt {3}}}{2}}={\sqrt[{3}]{|z_{0}|}}e^{i(-{\frac {\pi }{3}}+{\frac {\epsilon }{3}})}e^{\frac {2\pi i}{3}}=\cdots }](https://wikimedia.org/api/rest_v1/media/math/render/svg/637269119231828756b901f6cdfea68b8577ecef)
![{\displaystyle \cdots ={\sqrt[{3}]{|z_{0}|}}e^{i\left({\frac {\pi }{3}}+{\frac {\epsilon }{3}}\right)}={\sqrt[{3}]{|z_{0}|}}e^{i{\frac {\pi }{3}}}e^{i{\frac {\epsilon }{3}}}={\sqrt[{3}]{z_{0}}}e^{i{\frac {\epsilon }{3}}}=g(z_{0})e^{i{\frac {\epsilon }{3}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2c76eb4727fd30b37fa2d4557355584ab3689861)




- You don't need to compute any more limits this far in the game. Let be a point on the negative real line, and its circular open neighborhood avoiding the origin. Let be the unique branches of the cube root defined on such that , for , and for . All three functions are continuous by definition. Since you already proved , and by continuity, we obtain , hence . By a symmetrical argument, , hence is continuous in . — Emil J. 16:24, 6 October 2008 (UTC)
- I don't see how I can assume that there exist continuous branches of the cube root function on U. This problem is supposed to establish that one such branch exists. From the definition of a "branch of an inverse function on U" (a right inverse function that is continuous on U), it's not clear that one exists when U is an open set that straddles the negative real line.... or is it? How do we know that there exist continuous functions satisfying the conditions you describe? What am I missing?
Isn't there an epsilon-delta argument that someone can help me put together? Do we have to avoid that? I'm not married to the epsilon-delta format, but it's what I used for the square root function when I proved that it was uniformly continuous on certain domains, and it seems to be the flavor of proof that we usually use.
On a side note, the argument at z=0 doesn't have to be made, because g is defined on the domain -GTBacchus(talk) 19:47, 6 October 2008 (UTC)
- I don't see how I can assume that there exist continuous branches of the cube root function on U. This problem is supposed to establish that one such branch exists. From the definition of a "branch of an inverse function on U" (a right inverse function that is continuous on U), it's not clear that one exists when U is an open set that straddles the negative real line.... or is it? How do we know that there exist continuous functions satisfying the conditions you describe? What am I missing?
- You don't need to compute any more limits this far in the game. Let be a point on the negative real line, and its circular open neighborhood avoiding the origin. Let be the unique branches of the cube root defined on such that , for , and for . All three functions are continuous by definition. Since you already proved , and by continuity, we obtain , hence . By a symmetrical argument, , hence is continuous in . — Emil J. 16:24, 6 October 2008 (UTC)














- I may be mistaken, but isn't there some general theorem which guarantees the existence of branches of inverse functions on simply connected domains? Anyway, in this particular case, it is easy to define the branches explicitly. In fact, now that I think about it, it is possible to define directly a branch of cube root on the whole of , giving a completely limit-free argument avoiding the "step 2" above. (Sorry, I'm not in an epsilon-delta mood.) The argument is as follows.

- Define the function
- for . Obviously , and being a composition of continuous functions, h is continuous, thus it is a branch of the cube root on . Now it suffices to show that g = h. Consider such that . As , we compute easily . As , the difference is an integral multiple of , hence in fact . Also , thus . The case is similar. — Emil J. 10:16, 7 October 2008 (UTC)
- Define the function
- Not in an epsilon-delta mood, eh? No one seems to be. I guess if I want to use this problem to practice that, then I'm on my own. Whatever.
I talked to a few people yesterday, and came up with a couple of alternative strategies. The one you suggest is elegant, and works. Another option, which has a nice geometric appeal, is to define a different branch of the argument function, say arg(z) (lower-case 'a') where the range is the interval [0,2π), and establish that it is continuous. Then we could define , and show that g=h.
Anyway, I suspect this horse is dead, and I thank everyone for their help. -GTBacchus(talk) 14:50, 7 October 2008 (UTC)
- Oh, and that theorem about branches on simply connected domains may exist, but we haven't got it yet in our class, so I probably shouldn't use it. -GTBacchus(talk) 15:12, 7 October 2008 (UTC)
![{\displaystyle h(z)={\frac {1+i{\sqrt {3}}}{2}}{\sqrt[{3}]{-z}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1c65f53cc0dca7afc8879dedcaadde516cbf0c6c)





![{\displaystyle {\rm {Arg}}(z)\in (0,\pi ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d561120f6c2517c7f2080f9dddb1f12d915777c2)
![{\displaystyle {\rm {Arg}}(g(z)),{\rm {Arg}}(h(z))\in (0,\pi /3]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b233fe3a57dc65441abc436be37435181c26d998)






![{\displaystyle h(z)={\sqrt[{3}]{|z|}}\cdot e^{\frac {arg(z)}{3}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5265936bae9288473c535e91c6048d3a3119cb14)
Expressions
Hi. I've wondered for a long time, but never bothered asking anyone, is whether or not the expression is always equal to 1 or is always equal to x. My basic algebraic skills are quite strong and I can easily simplify the afore mentioned expressions but my problem lies in what happens to these expressions, as well as others of a similar nature, when you let x equal zero. Can anyone shed some light on the matter please? Thanks 92.3.238.32 (talk) 16:28, 2 October 2008 (UTC)


- When x equals 0 they are formally undefined. However, for a particular application, one can define them to be whatever is convenient or useful. Typically this would be their respective limits as x approached 0. Thus in your cases, it could be reasonable to define them as 1 and 0 respectively, although note that that is merely a convention you would choose to maintain. In other words, you cannot prove it, unless you did so circularly without realizing it. Baccyak4H (Yak!) 16:47, 2 October 2008 (UTC)
- These expressions have a removable singularity at . (Unfortunately, that article as currently written makes little sense to anyone not already familiar with complex analysis.) —Ilmari Karonen (talk) 20:31, 2 October 2008 (UTC)





- To answer this question with precision we need to distinguish between formal expressions and functions. As formal expressions, is algebraically equal to because we can convert the first expression into the second following the formal rules of algebra - in this context, is a formal variable and takes no values. Similarly the expression is also algebraically equal to the expression . However, once we start to talk about specific values of , we enter the realm of functions. And as functions, , and are three different functions of - the first is defined everywhere, the second is not defined at 0 and the third is not defined at 1. Gandalf61 (talk) 09:36, 3 October 2008 (UTC)


Find an analytic function f(z) such that f(f(z)) = exp(z)
Count Iblis (talk) 23:11, 2 October 2008 (UTC)
- I asked this a few years back. Wikipedia:Reference desk archive/Mathematics/February 2006#"square root" of exponential function. I asked on the newsgroup sci.math and sci.math.research, also. — Arthur Rubin (talk) 23:43, 2 October 2008 (UTC)
- [1] (Google groups, 1992) states that
- C Horowitz "Iterated Logarithms of Entire Functions" ISRAELI JOURNAL OF MATHEMATICS, v29, n1, pp. 31-42 (1978).
- provides an entire solution of h(z+1)=exp(h(z)), meaning that f(z)=h(h-1(z)+.5) will work. I've never actually checked it out, though. — Arthur Rubin (talk) 00:28, 3 October 2008 (UTC)
- That analysis seems to assume that "h" is 1-1, which is clearly not possible for an entire function. Sorry about that. It appears I wasn't paying attention to the answer in 1992, either. — Arthur Rubin (talk) 00:34, 3 October 2008 (UTC)
- There must be hundreds of people who've spent odd moments on this, it really deserves its own article. I came to the conclusion years ago no analytic solution was possible though I'm willing to be proved wrong as I've not read anything about it - it seemed more the sort of thing to just mess around with. An interesting path it led me to was considering things like (x+f(x)/n) iterated n times where n tends to infinity and mixing two such functions up in various ways. But I bet there's probably been named and got papers on it too by now. Dmcq (talk) 08:57, 3 October 2008 (UTC)
- Arthur, Thanks anyway, that article looks interesting! Dmcq, so, perhaps we need to think in terms of conformal algebra. The question is then: what is the generator of the exponential function? Count Iblis (talk) 15:50, 3 October 2008 (UTC)
- We have an article called half iterate that seems to be about this, although it has almost no content. --128.97.245.105 (talk) 21:18, 3 October 2008 (UTC)
- We also have a tiny article functional square root. I can't currently see a reason to keep both. Algebraist 01:22, 4 October 2008 (UTC)
October 3
Imaginary Numbers
Hello. Does i4a = 1 because (i4)a = 1a = 1? There are no parameters onto which set of numbers a must belong. Is there any amibugity? Thanks in advance. --Mayfare (talk) 00:10, 3 October 2008 (UTC)
- 1(3/2) = (e(2iπ))(3/2) = -1 (just kidding ;), 1a = 1 for any a. hydnjo talk 02:16, 3 October 2008 (UTC)
- (e/c) i4a=1 only if a is an integer. Going from i4a to (i4)a does not follow order of operations. If a= 3/4, we get i4•3/4=i3=-i. Paragon12321 02:53, 3 October 2008 (UTC)
- This is another question where wikipedia ought really have a special article. I just had a look for a paradox based on it by Thomas Clausen (mathematician) because I was feeling evil, but I can even find it using google. Dmcq (talk) 09:19, 3 October 2008 (UTC)
- Actually, there's nothing wrong with i4•3/4=(i4)3/4=13/4. You just have to remember that the complex exponential is multivalued, and you have to take the right value of the right-hand-side. The values of 13/4 are 1, -1, i and -i. Algebraist 09:23, 3 October 2008 (UTC)
- Hmm perhaps I'll just put in a version of that paradox by Clausen:
- e2πin = 1 for all integer n
- e1+2πin = e
- (e1+2πin)1+2πin = e
- e1+4πin-4π2n2 = e
- e.e-4π2n2 = e
- e-4π2n2 = 1
- This is plainly false for any integer n except 0 but the original line was true for all integer n Dmcq (talk) 09:47, 3 October 2008 (UTC)
- Hmm perhaps I'll just put in a version of that paradox by Clausen:
- I think I'll go an put something into the 'Powers of complex numbers' section of the exponentiation article as it doesn't treat the multiple results of powers very well - which is basically what Clausen's paradox exploits. Also whilst the Logarithm article does say the complex logarithm is multiple valued it doesn't explicitly put in the 2πin. Dmcq (talk) 09:32, 8 October 2008 (UTC)
Margin of error question...?
If I ask a question to a simple random sample of 8 individuals out of a population of 40, and 1 out of these 8 say yes, then the percentage of yesses is 12.5% But how do I calculate the margin of error for, let's say, 90% confidence.? What formula could I plug all those numbers in?--Sonjaaa (talk) 14:59, 3 October 2008 (UTC)
- Statistics isn't my area, so I don't feel confident giving you a definite answer, but Sample size#Estimating proportions looks like the place to start. --Tango (talk) 15:28, 3 October 2008 (UTC)
The population size is and the sample size is . The sample number of yeas is and the sample number of nays is . The population number of yeas, , assumes values from 1 to 33, and the population number of nays, , assumes values from 7 to 39. The number of ways to obtain is the product of binomial coefficients These 33 numbers are 15380937 25240512 30886416 33390720 33622600 32277696 29904336 26926848 23666175 20358000 17168580 14208480 11544390 9209200 7210500 5537664 4167669 3069792 2209320 1550400 1058148 700128 447304 274560 160875 89232 46332 22176 9570 3600 1116 256 33. Their sum is 350343565, which happens to be equal to The general distribution function for is actually but I am not going to prove it here. The accumulated values are 0.04 0.12 0.2 0.3 0.4 0.49 0.57 0.65 0.72 0.78 0.82 0.86 0.9 0.92 0.94 0.96 0.97 0.98 0.99 0.99 0.99 1 1 1 1 1 1 1 1 1 1 1 1 for 1..33. So a 90% confidence interval is or . Bo Jacoby (talk) 19:21, 4 October 2008 (UTC).


















Please help in German–English maths translation
Borsuk's conjecture#Conjecture status waits for someone to verify a translation from German. --CiaPan (talk) 15:01, 3 October 2008 (UTC)
I can provide you the final English translation of that quotation on Saturday (tomorrow) if you answer my stats question above today... :) --Sonjaaa (talk) 15:21, 3 October 2008 (UTC)
Grading on a Curve: Percents, Percentiles, and Z-Scores
Let us say that there is a college class with 100 students, and this group is being co-taught by two professors. Philosophically, Professor X and Professor Y agree that ideal grade distributions are: 10% A, 20 % B, 40 % C, 20% D, and 10 % F. At the end of the year, each professor independently grades the class and this is how they grade. Professor X rank-orders the students' scores, high to low, from 1 to 100. Then, Professor X assigns an "A" grade to students ranked 1 through 10; a "B" grade to students ranked 11 through 30; a "C" grade to students ranked 31 through 70; a "D" grade to students ranked 71 through 90; and an "F" grade to students ranked 91 through 100. Professor Y approaches the task differently. Professor Y calculates a z-score for each student. A student whose z-score is at or above the 90th percentile (z = 1.28) earns an "A" grade. A student whose z-score is at or below the 10th percentile (z = -1.28) earns an "F" grade. And so forth with the appropriate z-score cut-offs for the "B" and "C" and "D" students. (To make the conversation easier, let us assume that there are no tie-scores and no tie-ranks at all.) Question 1: Will Professor X and Professor Y ultimately have the same final grades for the same students ... or will each method give different results? Question 2: If the results are different, why is that exactly? Question 3: If the class scores are (or are not) normally distributed, does that make any difference or not? Thanks. (Joseph A. Spadaro (talk) 16:58, 3 October 2008 (UTC))
- It all depends on the distribution of marks. Consider the case where 1 student gets 100%, 1 gets 99.99%, 1 gets 99.98% and so on for the first 50 down to 99.51% and the other 50 have a similar distribution in the range 0% to 0.49%. Prof X will get the ideal grade distributions, but Prof Y will get half B's and half D's (if I've calculated it correctly). The difference is because Prof X forces the grades to be exactly the ideal distribution whereas Prof Y calculates the grades based on individual marks and weights it so that the expected distribution for a normally distributed set of marks will be the ideal distribution. The actual grades will depend on the actual marks, just because a variable is normally distributed doesn't mean a sample will follow that distribution exactly (or even at all for a small sample). I would say Prof Y has the better method, since how good a student you are doesn't actually depend on how good your peers are - some years are just cleverer than other years due to all kinds of influences (including random fluctuation). As long as you try and keep the exam difficulty the same from year to year (not always easy, admittedly), then you'll get fair grades. --Tango (talk) 00:11, 4 October 2008 (UTC)
- Thank you. Three follow-ups to your above comment. (1) If indeed the particular scores of this class were normally distributed, then Professor X's method and Professor Y's method will and should yield the exact same results ... is that correct? (2) To paraphrase, are you saying something along the lines of the following? Professor Y is basing his system on an idealized (normal) distribution, and then superimposing his actual student performance over that theoretical student performance (normal distribution). Professor X is artificially assuming that his group is indeed ideal (normal), whether they are or not. Is that what you are in essence saying? (3) You make the statement that: "Prof Y has the better method, since how good a student you are doesn't actually depend on how good your peers are." Under Professor Y's system, your entire grade (via your z-score) is indeed based on the performance of your peers, no? That is the very definition of your z-score ... comparing you with those being evaluated along with you. A student's z-score derives from the overall class mean and standard deviation. And thus, how well I do (via my z-score) is indeed contingent upon my comparison to my peers and how well they do. Is that not correct? Thanks. (Joseph A. Spadaro (talk) 01:19, 4 October 2008 (UTC))
- 1) Yes, I think so (to the extent that it makes sense to say that a sample is normally distributed - I think it's better to say that it's representative of a normal distribution, although that may just be me). 2) Not really, Prof X's method doesn't involve a normal distribution in any way. 3) Yes, good point. It does depend on your peers, but only via the class performance as a whole rather than individual peers, which is why it is better. It would be better still to calculate the z-scores compared to the last few years data which would account for differences between cohorts (although it requires consistent exams, which can be hard to achieve, especially if the syllabus changes). --Tango (talk) 12:17, 4 October 2008 (UTC)
- Thank you. Three follow-ups to your above comment. (1) If indeed the particular scores of this class were normally distributed, then Professor X's method and Professor Y's method will and should yield the exact same results ... is that correct? (2) To paraphrase, are you saying something along the lines of the following? Professor Y is basing his system on an idealized (normal) distribution, and then superimposing his actual student performance over that theoretical student performance (normal distribution). Professor X is artificially assuming that his group is indeed ideal (normal), whether they are or not. Is that what you are in essence saying? (3) You make the statement that: "Prof Y has the better method, since how good a student you are doesn't actually depend on how good your peers are." Under Professor Y's system, your entire grade (via your z-score) is indeed based on the performance of your peers, no? That is the very definition of your z-score ... comparing you with those being evaluated along with you. A student's z-score derives from the overall class mean and standard deviation. And thus, how well I do (via my z-score) is indeed contingent upon my comparison to my peers and how well they do. Is that not correct? Thanks. (Joseph A. Spadaro (talk) 01:19, 4 October 2008 (UTC))
- Re (2). No, professor X is making no assumption whether the distribution is a normal distribution or not. He simply forces the 'ideal grade distribution' to be true each year, without regard to whether the students this year are better or worse than the students last year. If the answers and grades from two years are compared, the results may be unfair. The ambitious student selects a class of stupid peers in order to obtain a high grade. Basicly, both professors are cheeting. The grade should reflect the competence of the student, and not that of his peers. Bo Jacoby (talk) 04:38, 4 October 2008 (UTC).
- An interesting case of normalizing scores happens with setting up IQ tests where the normalization involves ranking the scores for a test sample of people and projecting them onto a normal distribution. So the z-score will be exactly the same for that sample. The distribution of types of questions can also be altered so different groups of people get the same average - this is to avoid bias! Dmcq (talk) 12:23, 4 October 2008 (UTC)
- That's too what I was trying to avoid thinking about. IQ tests are done like that also. They grade people like prof Y. For example, the IQ test which I'm studying and have trouble accepting, is vulnerable to the scenario mentioned. It would be possible for the clusters of scores to skew the Z-scores in a way that makes no intuitive sense. Sentriclecub (talk) 13:18, 4 October 2008 (UTC)
- For an IQ test to work they need to use a large enough sample for the normalisation so that the risk of clusters like that is minimal. The IQ reported is basically a z-score, just expressed in a different way (z-scores are arranged so the mean is 0 and the standard deviation is 1, for an IQ the mean is 100 and the standard deviation is fixed, although what's it's fixed to varies from test to test). --Tango (talk) 15:19, 4 October 2008 (UTC)
- That's too what I was trying to avoid thinking about. IQ tests are done like that also. They grade people like prof Y. For example, the IQ test which I'm studying and have trouble accepting, is vulnerable to the scenario mentioned. It would be possible for the clusters of scores to skew the Z-scores in a way that makes no intuitive sense. Sentriclecub (talk) 13:18, 4 October 2008 (UTC)
- An interesting case of normalizing scores happens with setting up IQ tests where the normalization involves ranking the scores for a test sample of people and projecting them onto a normal distribution. So the z-score will be exactly the same for that sample. The distribution of types of questions can also be altered so different groups of people get the same average - this is to avoid bias! Dmcq (talk) 12:23, 4 October 2008 (UTC)
Follow up
Thanks to all for the above comments. Here is my follow-up question. In the world of education (specifically, higher education) ... or even in the world of math / statistics / testing / evaluation / etc. ... is there any accepted "standard" of grade distribution? In the above example, I simply (and conveniently) "made up" the distribution of 10%-20%-40%-20%-10% for the A-B-C-D-F grade ranges. Are there any statistically sound or generally accepted distributions? Thanks. (Joseph A. Spadaro (talk) 14:46, 4 October 2008 (UTC))
- Not really. See grade inflation for one thing that stops such a distribution from existing. --Tango (talk) 15:19, 4 October 2008 (UTC)
- If you want a mathematically justified choice of grade distribution, you could choose a uniform distribution (i.e., 20%-20%-20%-20%-20%). This choice of distribution maximizes the information conveyed by a single grade. However, this choice ignores the non-mathematical issues which dominate the choice of a grade distribution. Eric. 131.215.159.210 (talk) 10:20, 5 October 2008 (UTC)
- I guess that I would like to know ... what percent of a distribution would (statistically) be considered "exceptional", what percent would be considered "above average", "average", "below average", etc. Alas ... it is probably circular. The grade of A ("exceptional") means whatever X% the professor considers to be exceptional. Just wondered if there were any standards across fields of statistics / testing / psychology / measurements & evaluation / etc. Thanks. (Joseph A. Spadaro (talk) 21:47, 5 October 2008 (UTC))
- Thanks. I will look at that article. (Joseph A. Spadaro (talk) 14:57, 6 October 2008 (UTC))
- My impression, based on a few years of teaching nights at a local college, is that there is a three part distribution; the A students identify themselves and so do the F students; the B-C-D folks might follow a Gaussian distribution. Gzuckier (talk) 15:40, 6 October 2008 (UTC)
Thanks to all for your input on my question. Much appreciated. (Joseph A. Spadaro (talk) 01:10, 7 October 2008 (UTC))
October 4
request for solution for maths question
Upon solving the system of equation x15y17=r and x2y7=s for x and y, the answers always turns out to be of the form x=r^a/s^b and y=s^c/r^d where a, b, c and d are positive integers. Calculate the sum of a + b + e + d .
Ans: 31 Invisiblebug590 (talk) 10:24, 4 October 2008 (UTC)
- Assuming you mean:
- then I get the following simultaneous equations:
- which has a unique solution, but not one where a, b, c and d are integers, neither is their sum 31. Gandalf61 (talk) 11:00, 4 October 2008 (UTC)








maths question
the 2 squares in the diagram have side length 1cm, find the area of the slanted rectangle ABCD.
-
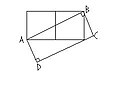 pls help
pls help

- Sounds like homework which is a no no here. But as a hint your teacher was probably recently moving triangles around or else was doing similar triangles or else was doing the Pythagorean theorem. Dmcq (talk) 12:01, 4 October 2008 (UTC)
- You'll find that the little right-angled triangle at the right is similar to the one whose hypotenuse is the diagonal of the original (two-square) rectangle, which should enable you to find the length of the sides of the slanted rectangle.…81.132.235.170 (talk) 14:24, 4 October 2008 (UTC)
There's a quicker way: (1) snip off the triangle with vertices B and C and the third point on the vertical line downward from B, and paste it on the left edge of the figure, getting a triangle below the original rectangle having one vertical side on the left and one horizontal side along the bottom of the original rectangle. (2) Now take the latter-mentioned triangle and turn it over and place it on top of the triangle that is the part of the original rectangle that is above the depicted diagonal. You see that the new rectangle has the SAME area as the original rectangle. Michael Hardy (talk) 21:57, 4 October 2008 (UTC)
- ...or yet another way: Consider the triangle where the two rectangles overlap. The area of that triangle is exactly half of the area of either of the two rectangles; therefore the two rectangles have equal areas. Michael Hardy (talk) 23:12, 4 October 2008 (UTC)
- You can add more and more rectangles going round in a spiral like in the Spiral of Theodorus which approximates the Archimedean spiral. Any idea what this one would approximate or does it stop going round? Just daydreaming, thought that was better than doing homework. Dmcq (talk) 09:38, 5 October 2008 (UTC)
- A nice problem. Translate the geometry into algebra. Take the rectangle as unit of area. Represent the sides by complex numbers, a and b. The direction of a is â and the length of a is |a|, so a = â·|a|. The direction of b is iâ and the length is |a|−1, so b = iâ·|a|−1 = ia·|a|−2 = ia·(aa*)−1 = i·(a*)−1 where a* is the complex conjugate of a. The proces of replacing a rectangle by the new one is a → a+b = a+ i(a*)−1. A numeric experiment shows that the first turn is after replacement number 28, the second turn is after replacement number 96, and the third turn is after replacement number 203. It doesn't look like if it stops turning, but it is too early to make a conclusion. Bo Jacoby (talk) 22:16, 5 October 2008 (UTC).
- Continuing. If an =10, then an+1 = an+ i(an*)−1 = 10+0.1i = 10·e0.00005+i·0.01. One turn is made after about 2π/0.01 = 628 steps and an+628 = 10·(e0.00005+i·0.01)628 = 10.32. So the spiral is much more tightly wound than the Archimedian spiral. I doubt if |an| → ∞. Bo Jacoby (talk) 12:06, 7 October 2008 (UTC).
The logics of significance and insignificance
So my question is not as interesting as the headline might suggest, but here goes:
Is it correct to say that the statements "X is not insignificant" and "x is significant" are not logically equivalent? And would it be correct to say that this is so because the opposite of "significant" is "not significant", and not "insignificant"? Also: is there a way to show this using predicate logic? (Don't worry: this is not a homework, I just had a discussion about it today with a lawyer-friend). —Preceding unsigned comment added by 83.250.105.19 (talk) 17:58, 4 October 2008 (UTC)
- Yes, I agree with your conclusion ... and I also agree with your reasoning behind it. Perhaps a more intuitive example helps us to understand the question you have raised. Statement A ("The odor is pleasant.") means something different than Statement B ("The odor is not unpleasant."). I think that the main distinction is that there can exist some middle neutral ground ... a continuum somewhat along the lines of: unpleasant odor -----> neutral odor (or non-odorous at all, even) -----> pleasant odor. Thus, an odor that is "pleasant" is pleasant. However, an odor that is "not unpleasant" may either be (a) pleasant ... or ... (b) neutral. If an odor is "not unpleasant", that does not necessarily mean that it must belong to category "a" (pleasant odors), since it can also belong to category "b" (neutral odors). And items in category "b" are items different than those called "pleasant odors" (namely, they are neutral odors). Thanks. (Joseph A. Spadaro (talk) 18:15, 4 October 2008 (UTC))
- What if "significant" means "known to be significant" and "insignificant" means "known to be not significant" etc? —Preceding unsigned comment added by 65.110.174.74 (talk) 21:09, 4 October 2008 (UTC)
- That's a bit philosophical for me... "If the probability of falsely rejecting the null hypothesis is less than 5% but nobody knows it, is it significant?" (cf. If a tree falls in a forest). --Tango (talk) 21:16, 4 October 2008 (UTC)
- I took the original question to be generic for any adjective ... not specific to the adjective "significant". I assumed that the original poster was asking whether or not the adjectives "X" and "not un-X" (or "not in-X") are logically equivalent ... regardless of which adjective "X" is considered. Granted, some adjectives are more prone to having a neutral intermediate than others. (Joseph A. Spadaro (talk) 23:55, 4 October 2008 (UTC))
- Yes, that was exactly my question. Thanks a lot for everybody's input. —Preceding unsigned comment added by 83.250.105.19 (talk) 07:24, 5 October 2008 (UTC)
- I took the original question to be generic for any adjective ... not specific to the adjective "significant". I assumed that the original poster was asking whether or not the adjectives "X" and "not un-X" (or "not in-X") are logically equivalent ... regardless of which adjective "X" is considered. Granted, some adjectives are more prone to having a neutral intermediate than others. (Joseph A. Spadaro (talk) 23:55, 4 October 2008 (UTC))
- Don't know if you're interested in this side of it, but a fair bit of research has been done in logical systems with more than two truth values. One of the results of this research is fuzzy logic. Black Carrot (talk) 07:27, 5 October 2008 (UTC)
- Incidentally, I'm not sure I'd say that the "unpleasant", "not unpleasant", "pleasant", and "not pleasant" lie on any kind of a continuum. Unpleasantness describes the existence of something disagreeable. Pleasantness describes the existence of something agreeable. Each lies on a continuum of its own, from "very X" to "not very X". I would say that "not significant" and "insignificant", however, are describing different parts of the same range from "very significant" to "not very significant". So that, for instance, in designing a fuzzy logic description these three would each have a rating from 0 to 1 attached to them. Black Carrot (talk) 07:51, 5 October 2008 (UTC)
Definite matrix
I am reading a paper on the work of Wilhelm Cauer which uses the phrase "positive definite matrices" in regard to the n x n matrices L, R and D in this equation,

I get the "positive" bit (I think) but am not so sure about "definite". The paper is written in English by a German so there may possibly be a language issue. I thought at first it just means "positive real" but later on we have -
"A key problem is the simultaneous principle axis transformation of two quadratic semi-definite forms (as opposed to the standard case where at least one form is non-degenerate)."
Which implies that I actually haven't understood a thing and "definite" means something else. Anyone know what? SpinningSpark 18:29, 4 October 2008 (UTC)
- You can't separate "positive" from "definite"; it's a single term, positive definite. See positive-definite matrix. --Trovatore (talk) 18:43, 4 October 2008 (UTC)
- Ta very much, quick answer, slow to look at it. SpinningSpark 21:36, 4 October 2008 (UTC)
"Undiscovered integer"?
In one of his books(I think The Demon-Haunted World) Carl Sagan suggests the thought experiment: "What if there is an undiscovered integer between six and seven?"(followed up by a question about the possibility of an undiscovered chemical element whose atomic number is that of the new integer). Does the idea of an undiscovered integer have any sort of meaning at all, or is this more likely intended to suggest, like many paradoxical thought experiments, that our grip on reality may not be as good as we think? 69.107.248.106 (talk) 20:52, 4 October 2008 (UTC)
- Seven is usually defined to be the next integer after six (see Peano axioms), so in that sense there can't be an integer inbetween. However, there is a difference between the mathematical concept of integers and the real life concept of collections of discrete objects. We model those discrete objects as integers, but that model could conceivably be flawed (well, I can't conceive how that would work myself, but the point stands that mathematical models are not absolute in the same way that mathematics is [if you ignore Gödel, anyway...]). --Tango (talk) 21:13, 4 October 2008 (UTC)
- You mean like the extra hours in a day that only managers know about? :) Dmcq (talk) 21:17, 4 October 2008 (UTC)
- More seriously for people with Dyscalculia often really wouldn't notice if a few numbers were missing. In fact I think most probably all people have blindnesses of one sort or another. Some people just can't give a greater weight to something that's bigger or see that a lot of small bits can add to a large amount. Probabilities are a complete haze. Ask what shape you get if you stick a corner of a cube into some plasticine and many people will say four. Personally I can see colours perfectly well but the colour of my front door is something I have explicitly learned because it seemed so silly not to know it when asked. Dmcq (talk) 21:40, 4 October 2008 (UTC)
- Microsoft Supercomputer Discovers New Integer Between 5 and 6 - Fredrik Johansson 22:18, 4 October 2008 (UTC)
- In the Internal Set Theory approach to non-standard analysis the natural numbers turn out to contain "non-standard" elements, even though the set of naturals is exactly the same as we usually think of it. In some sense these non-standard naturals are undiscovered and undiscoverable - it's not possible for 379274, or any other integer you might think of, to be non-standard, because it is "uniquely defined by a classical formula". To quote Robert's book Nonstandard Analysis (in Dover, everyone should get one), "These nonstandard integers have a certain charm that prevents us from really grasping them! Their existence is axiomatic". 163.1.148.158 (talk) 11:03, 5 October 2008 (UTC)
- In first-order Peano arithmetic, there exist models in which nonstandard elements exist. They have the properties of natural numbers required by the axioms, but they aren't natural numbers (generally, they live 'above' the natural numbers, and succeed each other in various patterns). They're sometimes called alien intruders, because "they live among us". Maelin (Talk | Contribs) 11:36, 5 October 2008 (UTC)
- According to our article (and my limited understanding), there can't be any nonstandard elements between six and seven—they always come after all the standard natural numbers. Of course, no one ever said you have to believe the Peano axioms in the first place. People have from time to time expressed doubts that a function with the properties ascribed to S actually exists, or that Peano induction is valid. -- BenRG (talk) 12:50, 5 October 2008 (UTC)
- There certainly isn't a non-standard integer between 6 and 7 --- such a number wouldn't be an integer. I brought up nsa in response to the second part of the question. 163.1.148.158 (talk) 13:49, 5 October 2008 (UTC)
- Oh, agreed. I didn't mean to suggest that those nonstandard elements could lie between the standard natural numbers. I was just mentioning them out of interest. It would be a pretty crummy arithmetic system indeed if it allowed elements to lie between six and seven. Maelin (Talk | Contribs) 01:16, 6 October 2008 (UTC)
- What if there's an undiscovered (or forgotten) letter between C and D and nutrition deficient in the vitamin for that letter is the cause of lots of illnesses in humans? – b_jonas 13:26, 5 October 2008 (UTC)
- Then we're all doomed, doomed! --Tango (talk) 16:31, 5 October 2008 (UTC)
- And since we're not doomed . . . Zain Ebrahim (talk) 13:20, 6 October 2008 (UTC)
- Then we're all doomed, doomed! --Tango (talk) 16:31, 5 October 2008 (UTC)
- [2] [3] [4] Black Carrot (talk) 03:22, 6 October 2008 (UTC)
- If you like this sort of thing you might like reading some of Gregory Chaitin's stuff, like his number that is defined but can't be computed or some theorems being random. I think there's probably some really simple things which are inaccessible to our way of thinking and imagination, perhaps computers will tell us some of them. Dmcq (talk)
October 5
Complexity of solving a sparse linear system
I am interested in estimating the asymptotic average run-time complexity of solving a sparse system of linear equations using typical iterative methods. Neither of these articles seem to provide a definitive answer. I assume the matrix A is n × n, with up to k arbitrarily positioned nonzero entries in every row and column, and we are looking for an approximate solution with tolerance ε. Thanks for any insight or references regarding the matter. 77.126.196.252 (talk) 13:54, 5 October 2008 (UTC)
- Hi. Are you specifically not reducing the bandwidth? Once that is done the problem is much more deterministic. Saintrain (talk) 15:25, 5 October 2008 (UTC)
- I haven't considered that. The article mentions bandwidth reduction for symmetric matrices, which mine isn't, but I do not see why symmetry is necessary. If applicable, I do not exclude bandwidth reduction, or any other robust preprocessing. What would the complexity look like in this case? Thanks. 77.126.196.252 (talk) 19:59, 5 October 2008 (UTC)
- (Took me a while to remember back to the old days when things like this were important; modern PCs can handle "n"s of hundreds of thousands.) Not quite what you asked, and if I remember correctly (HA!), for a direct solution, the solution time will be about proportional to the sum of the A matrix column "heights" (up to the top-most non-zero element). Saintrain (talk) 23:31, 6 October 2008 (UTC)
- (P.s. none of our business, but what is it?)
October 6
Solution manual
is there an online solution manual for for A first course in Probability by Sheldon Ross (in downloadable electronic format)? —Preceding unsigned comment added by 203.128.4.231 (talk) 04:20, 6 October 2008 (UTC)
Julia set in nature
Is there anything in nature that has the structure of a Julia set? Mr.K. (talk) 11:58, 6 October 2008 (UTC)
- How about Fractal Structure of the Horsehead Nebula. Dmcq (talk) 12:49, 6 October 2008 (UTC)
- Are you looking for the Julia set in particular, or fractals in general? If it's the latter, the Fractal article has a section Fractal#In nature. -- 128.104.112.147 (talk) 00:05, 8 October 2008 (UTC)
October 7
Name
What's the name given to numeric 6's and 9's that have their thingos swinging out, like the ones in this font? February 15, 2009 (talk) 00:23, 7 October 2008 (UTC)
- What font? Wikipedia text is shown in your browser's default sans-serif font, which is probably not the same as my browser's default sans-serif font. Anyway, perhaps you're referring to text figures? —Ilmari Karonen (talk) 04:23, 7 October 2008 (UTC)
- I believe that "seriff" is the "feet" on letters such as i, l, t etc... But I believe the rule might be similar to whether or not a lowercase Q or a lowercase J gets curved at bottom, or just a straight line. Guessing from memory (and yes I had to learn this for a computer class) it might be Times, but there's also a rule of whether or not a W gets the same amount of width, as a lowercase L. Its interesting stuff, but your question about 6's for example, is probably the same answer as to the stipulation about lowercase Q and lowercase J. That might help you find it easier, since you can expand your question, i.e. a google search. Sentriclecub (talk) 10:45, 7 October 2008 (UTC)
- Try the article on font. Sentriclecub (talk) 10:46, 7 October 2008 (UTC)
- Swash (typography) that should be it. Each typeface has its own rules of whether or not to give swashes onto a 6 or 9. Sentriclecub (talk) 10:56, 7 October 2008 (UTC)
Compass and Midpoint
I recently encountered a problem related to geometry drawing, but did not find an article on it.
So basically, you have a compass. No ruler or anything else. This means you cannot draw a straight line. So given a line segment, use the compass to find the midpoint of it.
Anyways if there is any relevance in this, I thought it might be important to write an article related to geometry drawing? Any tips on the problem let me know ;).
--electricRush (T C) ![]()
![]() 03:23, 7 October 2008 (UTC)
03:23, 7 October 2008 (UTC)
- Are you absolutely sure that you do not have access to a straightedge? Because if you did, you could draw two congruent circles centered on the endpoints of the line segment. Then you would draw a line between the points of intersection between these circles, and then that line would intersect with the original segment at its midpoint. 206.117.40.10 (talk) 03:55, 7 October 2008 (UTC)
- Yes, for this problem you may not use a straightedge. All you can do is use the compass to draw circles. This problem is supposed to be very hard though... --electricRush (T C)

 04:08, 7 October 2008 (UTC)
04:08, 7 October 2008 (UTC)
- Can you access this file (PS)? It describes how to perform the operation. It also speaks of the (for me unknown until tonight) Mohr-Mascheroni theorem. Pallida Mors 06:52, 7 October 2008 (UTC)
- In case you can't handle the postcript, here there's a web site. Pallida Mors 07:04, 7 October 2008 (UTC)
- Yes, for this problem you may not use a straightedge. All you can do is use the compass to draw circles. This problem is supposed to be very hard though... --electricRush (T C)
- Even more amazingly see Weisstein, Eric W. "Matchstick Construction". MathWorld., you only need matchsticks to do anything a normal compass and straightedge can do. Dmcq (talk) 07:55, 7 October 2008 (UTC)
Infinite increase
If I have an integer, let's take 1, and I increase that integer at an infinite speed (or rate), does my number become infinite in a zero time period? —Anonymous DissidentTalk 07:40, 7 October 2008 (UTC)
- It's hard to increase an integer; they're pretty stubborn about staying just what they are. (An integer variable is another matter.)
- Extrapolating from your question, it's quite possible for a function to have infinite first derivative at a point and yet be pretty well behaved generally. (OK, technically, the derivative won't be defined at that point, but it's pretty obvious what "infinite first derivative" means.) An example is the cube-root function, whose derivative becomes infinite at zero, but (the original function) takes only finite values on the real line. --Trovatore (talk) 07:54, 7 October 2008 (UTC)
- From the concept of a massless string, the answer is yes. If you apply a net force to a massless string, it will accelerate infinitely and reach an infinite velocity, instantly. But you can't apply a force, before the force is applied, which is why your Q is a bit tricky. As soon as the instant you apply your force, say at t=2.7 seconds, then yes it instantly reaches infinite velocity. Oops, upon second thought, you would need an infinite acceleration, not an infinite speed (or rate). But since you're asking about the number reaching an infinite "position" (which i'm butchering your question now), then yes if you apply an infinite velocity to an object, it will instantly reach an infinite position. Just the same that a tiny net-force applied to a massless string will cause it to reach an instant infinite velocity, then the reasoning holds true about your original question. So the answer is yes but you could better clearify the last 5 words, since the word "instantly" is what you are asking, right? Sentriclecub (talk) 10:39, 7 October 2008 (UTC)
Correlation between shapes
I am looking for a formula which determines a correlation coefficient which measures the correlation between two shapes in a two-dimensional space. Each shape is given by connecting the heads of six vectors all pointing in independent directions with angles of 2*pi/6 radians between them. There are two shapes. If the two shapes are identical then the correlation should be one. If the shapes are pointing in opposite directions we would expect the correlation to be negative. The correlation coefficient should between minus one and plus one. Does anybody know how to construct such a formula? HowiAuckland (talk) 10:34, 7 October 2008 (UTC)
- I'm afraid you can't. Think again what 'the shapes are pointing in opposite directions' means.
- Imagine a regular hexagon, centered at the coordinate system's origin. Let P and Q be two opposite vertices of the figure. Make two new shapes by moving P and Q, respectively, a bit outside from their original positions. I suspect you would call it 'shapes pointing in opposite directions', thus assigning a correlation of −1 to that pair. However if the vertices displacement is small enough, the shapes stay 'almost' identical to each other (and to the original hexagon) so their 'correlation' ought to be close to +1.
- So we have a pair of shapes which deserve a correlation of −1 and +1 at the same time. How are you going to solve it?
- CiaPan (talk) 13:28, 7 October 2008 (UTC)
- Hi CiaPan. Thanks for your reply and you may very well be correct in your assertion. However, in your example just noted the second polygon isn't actually pointing in an opposite direction as the first polygon. In fact, the second polygon is equally pointing, the same amount, in both opposite directions, which is very similar to the first polygon, so I would expect the correlation to be close to +1. Your example has no assymetry, and therefore I expect the correlation to be close to +1. The negative correlation should come from an asymmetry between the two polygons. An example of two polygons which I think should give a negative asymmetry is if you took your example, and instead of stretching out both vertices P and Q equally, you simply stretch one side, say P. Now I would think this would have a negative correlation between these two shapes.
- A quandary that I have come across which has made me think that the problem might not be well-defined is if you take as your first polygon, a polygon with P stretch outward significantly in one direction, and the second polygon stretched outward at Q in the opposite direction, then you should get a negative correlation. However if you then look at the limit as the P and Q vertices are shrunk back to the same length as the other vertices from the center, then the correlation should get progressively negative but closer to zero. The quandary is that in that limit one might also expect the correlation to approach +1 since in that limit the two shapes are identical. Does anybody think that this example also indicates the possible non-well-posedness of the problem? HowiAuckland (talk) 20:53, 7 October 2008 (UTC)
- You could calculate the mean of the six points and measure the angle between the means for each shape (considered in polar co-ordinates). That would give you a number between 0 and pi, call it x. Then consider 1-2x/pi, does that satisfy your requirements? It would consider two shapes that are just simple scalings of eachother to be identical, is that a problem? --Tango (talk) 23:09, 7 October 2008 (UTC)
- This quantity would be undefined when the means for either shape add up to zero. HowiAuckland (talk) 23:36, 7 October 2008 (UTC)
- That's a good point, but I think that's due to your question. You talk about whether or not they are pointing in the same direction, but a regular hexagon doesn't point in any direction. --Tango (talk) 23:49, 7 October 2008 (UTC)
- Very true. Regular hexagon wouldn't point in any direction. However, the correlation between two identical shapes should always be +1, and if they are very similar it should be close to +1. (I think, subject to the quandary I listed above, which I can't resolve.) HowiAuckland (talk) 23:58, 7 October 2008 (UTC)
- That's a good point, but I think that's due to your question. You talk about whether or not they are pointing in the same direction, but a regular hexagon doesn't point in any direction. --Tango (talk) 23:49, 7 October 2008 (UTC)
- This quantity would be undefined when the means for either shape add up to zero. HowiAuckland (talk) 23:36, 7 October 2008 (UTC)
- If you're willing to skip regular hexagons, you could just literally use the correlation of the two sextuples of vector lengths. Then any other shape would have correlation 1 with itself and would typically have negative correlation with itself rotated or reflected. But you're not going to get perfect -1 in general. --Tardis (talk) 00:37, 8 October 2008 (UTC)
- Yes, I think this might be a good idea, except it seems to give strange results. As an example, in the case where you have all the lengths zero except one vector equal to 1 in the first shape, and then in the second shape you have all lengths to be zero except for the opposite direction with length of 1. Then this gives a correlation of −0.2. Similarly, if you take all lengths to be zero except for a single entry, regardless of position, to be one, you will always get a correlation of −0.2, even when the vectors in the two shapes are pointing nearly in the same direction. I would expect this case to give a positive correlation. Even though the sign is curious, certainly they shouldn't all give the same value of the correlation. They are entirely different shapes. HowiAuckland (talk) 01:35, 8 October 2008 (UTC)
side, edge of a circle
what is the difference between or the meaning of side of a circle and edge of a circle... How many sides does a circle have? How many edges does a circle have?
116.75.181.164 (talk) 10:43, 7 October 2008 (UTC)
- The boundary of a circle is neither called side nor edge, but circumference. So the short answer to your question is: zero sides and zero edges. However it does make some sense to say that the circle has an infinite number of sides, as it is approximated sufficiently well by a polygon having sufficiently many sides. Bo Jacoby (talk) 11:21, 7 October 2008 (UTC).
The 1-D Heat Equation
Help! I don't understand this Heat Equation stuff.
I have a problem with a semi-infinite cylinder of metal on the positive x-axis with sides and face at x=0 insulated. The heat will therefore diffuse according to the 1-D heat equation. The initial temperature distribution is , the end is insulated which indicates that .


I'm trying to solve this using Green's function, extended to the infinite axis as an even function, and then changing variables to get the error function. But I have been given the solution and no matter what I try I can't get to it. I don't think I understand exactly how to incorporate the initial value function as part of the integrand.
The solution given is
![{\displaystyle u(x,t)=(1/2)u_{0}exp(c^{2}t/L^{2})[exp(-x/L{1+erf((x-2c^{2}t/L)/{\sqrt {(}}4c^{2}t)}+exp(x/L){1-erf((x+2c^{2}t/L)/{\sqrt {4c^{2}t}}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/87e2a7d74f574bbeb185a17e9f35c29e3345da99)
If anyone can explain where this solution comes from I would really appreciate it. —Preceding unsigned comment added by 122.108.235.248 (talk) 13:49, 7 October 2008 (UTC)
- I suppose you mean . The c is unexplained. There are some missing parentheses in the formula which might have been
- where
- is the error function.
- Simplify the computations by choosing the unit of temperature to be , and the unit of length to be , and the unit of time such that . Then the formula looks like this:
- .
- The initial condition at t→0+ is
- .
- OK! Then check the other initial condition
- and the heat equation.
- Bo Jacoby (talk) 20:02, 7 October 2008 (UTC).

![{\displaystyle u(x,t)=(1/2)u_{0}\exp(c^{2}t/L^{2})[\exp(-x/L)(1+\operatorname {erf} ((x-2c^{2}t/L)/{\sqrt {4c^{2}t}}))+\exp(x/L)(1-\operatorname {erf} ((x+2c^{2}t/L)/{\sqrt {4c^{2}t}}))]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3cd04b3e43001542b245f13055727af7c7b17b22)




![{\displaystyle u(x,t)=e^{t}[e^{-x}(1+\operatorname {erf} ((x-2t)/{\sqrt {4t}}))+e^{x}(1-\operatorname {erf} ((x+2t)/{\sqrt {4t}}))]/2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8438d2fbf3f5a345e33d1c8b0bcc31da981063df)
![{\displaystyle u(x,0^{+})=[e^{-x}(1+\operatorname {erf} (x/0^{+}))+e^{x}(1-\operatorname {erf} (x/0^{+}))]/2\,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d144d51b80e8d353fec83d9c5750757f84202718)
![{\displaystyle =[e^{-x}(1+\operatorname {erf} (+\infty ))+e^{x}(1-\operatorname {erf} (+\infty ))]/2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/23da502b537397135f0d7bde4fb8fe6754321d5a)
![{\displaystyle =[e^{-x}(1+1)+e^{x}(1-1)]/2=e^{-x}.\,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1193678206ecc1dce9c9d0cba955db69ca64342a)


Simple statistics question
(related to Talk:Mongolia): Assuming that 800 children are born in a hospital in one year, and assuming that the probability that a newborn is a boy is 0.5 (feel free to calculate with a more correct value, but then tell me so), what is the probability of more than 430 of the newborn being girls?
My impression is that this should be roughly 0.025 (normal distribution, E=400, sigma square = 200). Anything wrong about this? Yaan (talk) 18:50, 7 October 2008 (UTC)
- Using a normal approximation should get a pretty good answer for n=800 (I haven't checked to see if you calculated it right, but the method is good). You could also do it directly as a binomial distribution (that article should have the formulae you need). The normal approximation is easier, though, if you don't need an absolutely precise answer. --Tango (talk) 18:59, 7 October 2008 (UTC)
- From human sex ratio, "The natural sex ratio at birth is estimated to be close to 1.1 males/female", so you need to take that into account. But your stat is the reverse!? Saintrain (talk) 19:48, 7 October 2008 (UTC)
The standard deviation is 2001/2=14.1421. The deviation of the observation from the mean is 430−400=30. And 30/14.1421=2.12133. The probability that a normally distributed observation is greater than the mean + 2.12133 standard deviations is 0.016947, or roughly 1/59, (as compared to 0.025=1/40). Bo Jacoby (talk) 21:17, 7 October 2008 (UTC).
- If you're going to claim so much accuracy, you should do a continuity correction using the fact that in this context, "> 430" is the same as "≥ 430.5". So
- and the probability that the standard normal exceeds that is about 0.015515, or about 1/64. Michael Hardy (talk) 01:08, 8 October 2008 (UTC)

![[3]](http://icanhascheezburger.files.wordpress.com/2007/07/doomed.jpg){kind=link}
October 8
Minimizing first-time comparisons
What's the best sorting algorithm that minimizes the number of first-time comparisons? This generally involves data that is expensive to initially compare (or otherwise can't be algorithmically compared), but once the initial comparison is made, the result can be cached.
After a new comparison is made, my system looks for things similar to A < B < C and ensures that A < C. It then searches the cache to find which pair eliminates the most combinations. Even though this works, I feel this may be the bottleneck, since a full search (probably O(n^4+)) could make the sorting much longer than it could, and a limited search (currently O(n^3)) may be less accurate.
I'm aware of a monte-carlo algorithm, but I'm not sure whether to go for that or the full-search in the comparison matrix. --Sigma 7 (talk) 02:29, 8 October 2008 (UTC)