This article is within the scope of WikiProject Mesoamerica, a project which is currently considered to be inactive.MesoamericaWikipedia:WikiProject MesoamericaTemplate:WikiProject MesoamericaMesoamerica articles
This article has been rated as B-class on Wikipedia's content assessment scale.
Please use the archive parameter to specify the number of the next free peer review page, or replace {{Peer review}} on this page with {{subst:PR}} to find the next free page automatically.
Mayance languages
I only get about 500 hits on google for "mayance maya", and one of the first two hits is wikipedia. Is this actually a significant enough term that it deserves to be bolded, with a two-sentence explanation?
Rather than saying "belief that it bears...", it seems to me that it would be simpler to say simply something like "The Maya of today are the direct descendants of the Classic Maya."
Ladino?!?!
Somebody please figure out what the reference to Ladino is doing in this article. Cbdorsett 20:13, 11 Feb 2005 (UTC)
Here it meant people of Hispanic culture. I changed it to be less ambiguous, but the Ladino and Ladinos articles need to be more clear on this and other alternative meanings for the term. -- Infrogmation 05:24, 12 Feb 2005 (UTC)
Infrogmation, I'm quite sure you are confusing the two terms Ladino and Latino. — Hippietrail 14:14, 12 Feb 2005 (UTC)
As I've both heard and read "Ladino" with the above meaning, I don't believe so. Either way, the possibly confusing term is now out of this article. -- Infrogmation 18:29, 12 Feb 2005 (UTC)
This issue is being dealt with. The Judæo-Spanish/Ladino article is now at Ladino language. Ladino is being changed to a disambig page (Ladino (disambiguation)) as I write this. TomerTALK 06:05, Mar 27, 2005 (UTC)
Doesn't "ladino" mean "astute"? Were the indigenous people who adopted the Spanish language and modern dress considered astute? David Brown CSULB dabro@csulb.edu Apr. 10, 2005
I have edited Ladino people to answer that question.
i have heard of people called ladinos, in central america. from what i can tell, they aren't connected to the ladino language spoken by sephardic jews.
Gringo300 12:54, 20 October 2005 (UTC)[reply]
Ladino is the expression used especially in Guatemala to refer to the europeanized peopulation called "Mestizo" in Mexico.Maunus 20:38, 11 August 2006 (UTC)[reply]
Removal of fringe material
I removed the reference to "Mayance languages". See comment above. Also see:
"There are various devices that have been used by scholars to disambiguate the term. One such attempt, which failed, was to introduce the term "Mayance" for the family, keeping "Maya" for the language. The current accepted terminology is to call the language "Yucatec" or "Yucatec Maya," saving "Maya" for the family."
I also removed the claim about an "African substratum". See discussion in Talk:Maya hieroglyphics.
i've recently begun doing research on the mayan tribes and languages.
i'm much more familiar with the ancient maya.
Gringo300 12:56, 20 October 2005 (UTC)[reply]
Oh my. well isn't that nice. Anything else? TomerTALK 12:18, 9 November 2005 (UTC)[reply]
Tzotzil
Shouldn't the pronunciation begin with [ts]? I'm assuming [s] is a typo? -- MikeGasser(talk) 15:10, 5 March 2006 (UTC)[reply]
Cordomex
This resource really should be mentioned---there isn't much reference on the web about this dictionary—The preceding unsigned comment was added by 66.176.186.65 (talk • contribs) 22 May 2006.
By all means, if you have the information, feel free to add something about it.--cjllw | TALK 23:57, 21 May 2006 (UTC)[reply]
ALMG
Here in Guatemala the Academia de Lenguas Mayas de Guatemala is considered the authority on Mayan languages and has updated the orthography. Even in Mexico they get some respect (in my experience in the Tzotzil area) and I expect that in Belize and Honduras too (given relative sizes of the populations involved and that there are no Mayan languages there that aren't also indigenous to Guatemala. I'd suggest it would be good to move all relevant pages to reflect the new orthography, keeping of course the old (Spanish) version redirects. (although I personally find the doubled vowels silly, but that's probably because the two languages I've touched don't have them) Here's my revision of the list:
I think the new spellings should be mentioned, but generally as far as I have udnerstood it is Wikipedia policy to use American English spellings, not native spellings, but the spelling that allow english speakers to most easily find a topic. Native names and spellings are generally provided in the article lead but not as the name of the article, e.g. the article is French language not "langue francaise"Maunus 20:41, 11 August 2006 (UTC)[reply]
Granted. But the American English basically follows the Spanish (or else why the gendered endings and the accent in Quiché, basically only the capitalization and the few non-gendered ones like Yucatec are particularly English). And the Spanish is clearly changing. Moreover, the forms currently used on this page are a mishmash, all the K's make it clear we're not using old style Spanish but then The adjectives Quichean and the like are clearly established in English, you don't change them, but I'd say the English trend is clearly to accept local changes into English. Certainly, we should at least have a coherent policy, for example, either include the glottalization as in Tz'utujil or not as in Kekchi. And a coherent policy is taking sides, you either follow individual-expert-X or you use the latest consensus spelling.
Let's see if anyone else has an opinion.--Homunq 17:52, 12 August 2006 (UTC)[reply]
Wow, I just found ISO_639 which actually DOES have a standard English for all of these, the problem is I highly doubt (based on the internal inconsistencies mentioned above) that the current list uses the correct names down the line, and I see no easy way to do the search (given, for instance, that Cakchiquel comes out with 7 dialects, whereas even in the Rosetta project it only has 5.) So, I support using the correct ISO 639 English naming, but mentioning the ALMG as the preferred native spelling. Does anyone know how to search the 639 codes? --Homunq 21:46, 12 August 2006 (UTC)[reply]
I think using the Academia's orthography would be an attractive option, with a number of advantages: it is (mostly) consistent, it was specifically developed for these particular languages, and (importantly) a significant and ever-growing number of contemporary sources in the field of Maya studies use it (and do so deliberately). That is to say, this orthography is increasingly used in the papers, journals and (to a lesser extent) books written on Maya topics which are cited as references for Maya-related articles- at least those from the 1990s onwards. AFAIK the ratified part of ISO 639 is concerned with standardising the language codes, not their names.--cjllw | TALK 13:34, 13 August 2006 (UTC)[reply]
Thanks, good to see someone who probably knows a lot more than I. What would you suggest for the Mexican languages and for the gendered endings? I think probably the "most English" answer would be to drop the endings, but the other way is probably more searchable; either way we should be consistent. Feel free to add your suggestions for specific languages above in some other formatting than the bold I've used, if it helps.
A note of context for those unfamiliar: these names are not the languages names for themselves. Most refer to themselves as "true language" or "our language" (for instance, Bats'il K'op in both Tzotzil and Tzeltal). If anything, these are the laguages' names for the ethnic groups (when disambiguation is necessary), though many of them have an Aztec (non-mayan) etymology. Should that go (edited) in the article itself?--Homunq 15:32, 13 August 2006 (UTC)[reply]
Contemporary english-language Mayanist sources which have adopted this orthography apply it to Mayan-originated terminology in general, including instances where the language or term "comes from" outside of Guatemala itself; so there should be no issue in extending it for Mexico-based instances such as Yukatek or Wastek, for example. A cautionary note: sources do differ a bit in the extent by which they apply the Academia orthography: some use it for all Mayan terms, while others retain the "old" orthography for certain instances such as 'well-established' place names, language names and ethnonyms. Still others continue to use a Spanish-accented orthography in some cases (probably a reflection that spanish is also a lingua franca among researchers in the field). See also the WP:MESO proposal and discussion for applying consistent orthography here. The proposal is based more on its usage in archaeological/epigraphic contexts, research publications on modern Mayan languages themselves might possibly be a little different, I'm not that sure. Regardless of all this, I'd still think that ALMG orthography is well-suited to the task.
Re whether or how to indicate gendered endings, I agree that the "most english-sounding" would be to drop the endings, but could be pursuaded otherwise if we could come up with some consistent reasoning. And as for the cases where the language names (even under revised ALMG orthography) are exonymic: I would say that yes, it would be great to mention in the article itself the name(s) of the language used by the speakers themselves as well as discussing the etymologies of the various terms, however titling the article that way would be going a step too far. I think it would be better to preserve the concordance between the names of the peoples and their languages, insofar as this is possible.--cjllw | TALK 00:09, 14 August 2006 (UTC)[reply]
I dont know what to prefer. I dont think following current wikipedia policies the Academia is the source to follow on an english language encyclopedia, I think that the article should be aimed at an english speaking audience and use the spelling for which they are more likely to search. On the other hand there are no reliable english standard either, not even within academia sso many languages have several names and even more spellings of these and it is a wilderness to try and decide which is more encyclopedic. I personally strongly dislike the gendered endings in an english context and feel that they will limit searchability quite a lot. Something I would like to see however would be a page on the academia and on reccomended orthographies in general and to have a link to this page on each of the separate language pages. Maunus 21:32, 14 August 2006 (UTC)[reply]
IMO we should not have too much of an issue in using ALMG orthography in an english language encyclopaedia, since it is adopted by a sizeable number of english language publications and works in the field. A general reader who has come across one of these contemporary sources would or should recognise the spelling (though equally I suppose a reader familiar with other or general sources will recognise different or former spellings). I can't really think of a way to establish with any confidence which spelling would be "most recognisable" to the general reader, particularly since it may be supposed that many of these languages are probably little-known outside of specialist areas.
Agree that it would be fruitless to attempt to determine which orthography is the most encyclopaedic, and that even within academic publications there are differences. Also, I'm more familiar with archaeological and epigraphic sources than modern linguistic ones- Maunus, are you or anyone else able to confirm whether modern Mayan languages research also has a general observance nowadays for ALMG conventions?
Even so, the ALMG system is a (or the) recognised authority here, and it at least does give reasonably comprehensive guidance on language representation. If our articles were to follow a system such as this, it will be less jarring to read than the current mix of othographical conventions within and between articles. There's also the danger that a reader could become confused as to whether similar spellings refer to the same entity, or really are referring to different ones. Of course, each article needs to give the explanation and list of orthographic alternatives.
In any case we'll have a number of redirects for each pointing to whichever spelling convention is chosen, so readers searching on any particular variation should hopefully end up at the desired target.
I think your idea on a general article covering orthographic standards, developments and concordance for Mayan languages is a good one.--cjllw | TALK 02:42, 15 August 2006 (UTC)[reply]
The following discussion is an archived debate of the proposal. Please do not modify it. Subsequent comments should be made in a new section on the talk page. No further edits should be made to this section.
The result of the debate was move, for the most part. -- tariqabjotu 03:33, 20 August 2006 (UTC)[reply]
OK, I'm nominating all of these for moves. I'll provide a link here for discussion. See just above for older discussion. If/when these moves happen, this page should be updated to reflect the new spelling, though generally the old should be left as a redirect (except for typo "Sikapense") --Homunq 21:13, 14 August 2006 (UTC)[reply]
OK here's the proposal from WP:RM. Feel free to cut and paste your own improved version...
Proposal specifics
This is a proposal to rename a number of articles on individual Mayan languages to a standardised orthography. Discussion for these moves is centralised here (note that a rename of this particular article, Mayan languages, is not part of the proposal).
This proposal combines several principles:
That the languages' names be standardised according to the orthography conventions adopted and preferred by the Academia de Lenguas Mayas de Guatemala (ALMG)[1], a (or the) recognised authority for these languages. Rationale: it provides a consistent standard recognised in the field and is (increasingly frequently) employed by major english-language sources often cited in Maya-related articles; see also WP:MESO/G for some further background.
That gendered endings (eg -o, -a) not be used. Rationale: not warranted in an english language context.
That each language article title be of the form [[xx language]]. Rationale: following widely-observed practice for articles on languages generally, and to readily distinguish from articles on the peoples themselves.
See also the discussion above.
Articles affected by the proposal, and their currently designated targets, are as follows:
The primary rationale for this move is to bring things in line with the ALMG conventions, see guideline in WP:MESO/G. While we're at it, we might as well standardize on not including the Spanish-style gendered endings (already the case for the larger languages), and using the "xx language" form (not "maya" which should be "mayan" anyway).-- Homunq 22:22, 14 August 2006 (UTC)[reply]
Survey
Add "* Support" or "* Oppose" followed by an optional one-sentence explanation, then sign your opinion with ~~~~
Support, in-principle at least, per reasons cited. I think the ALMG orthography provides a clear and recognised orthographic guideline, in the absence of which the articles and mentions of these languages in en.wiki are presently all over the place.--cjllw | TALK 05:50, 15 August 2006 (UTC)[reply]
Support Lets do it. Its worth it to have a standardized orthography.Maunus 06:21, 15 August 2006 (UTC)[reply]
Support ALMG standards are recognized "officially" in Guatemala, the only ones that make sense for Wikipedia (en, es, whatever). Thanks for taking this on. — MikeG(talk) 14:54, 15 August 2006 (UTC)[reply]
If anyone knows, please specifically comment on Chikomuseltek and Lacandon, I wrote the proposal but I'm not sure about these. --Homunq 09:49, 15 August 2006 (UTC)[reply]
Chicomuceltec is extinct so it doesn't really matter what it is called. I think it should be kept unchanged though, it is beyond the governance of ALMG and references are likely to use the "classic" orthography. Lacandon is also sometimes spelled Lakantun but I don't know the status of this orthography and would also prefer it to unchanged so that its connection with the "selva lacandona" is not blurred.Maunus 11:45, 15 August 2006 (UTC)[reply]
Discussion
I think you might be coining a new name with Yukatek Sign Language — it gets no google hits at all. "Yucatec Maya Sign Language" appears to be the standard designation. "Mayan Sign Language" gets a few hits, as does "Nohya Sign Language". Even Lenguaje Mímico Maya, Lenguaje Manual Nohya, and Lenguaje Manual Maya get a couple each. It's a little more complicated, as at least one writer describes a group of related mayan sign languages in Guatemala and Mexico, including Highland Maya Sign Language, or what K'ichee'an people call Meemul Ch’aab’al. I think your plan makes sense, but I am hesitant to support renaming the language if noone outside of wikipedia has done so. ntennis 23:51, 14 August 2006 (UTC)[reply]
The above discussion is preserved as an archive of the debate. Please do not modify it. Subsequent comments should be made in a new section on this talk page. No further edits should be made to this section.
Bloodletting
I have no idea how to edit the template that causes the box on the right, but I feel strongly that a link to the (classic) Mayan religious practice of bloodletting does not belong on a page about the (modern) Mayan languages. --Homunq 16:55, 13 August 2006 (UTC)[reply]
That template is more about covering the main topical areas relating to pre-Columbian Maya, so perhaps it could be removed from here altogether. However, I don't myself see the template as being out-of-place here, and note also that it is still very much under development & can and should be revised and expanded. I do agree that in terms of comparative levels of subject matter bloodletting does look out-of-place in that list, which should really be a collection of higher-level topic areas. I'll revise the template with something a little more general and widely-applicable.--cjllw | TALK 00:17, 14 August 2006 (UTC)[reply]
I dont even see why bloodletting is encyclopedic enough to have its own article. Let alone be shown as a "general maya related article"". Sounds like you are going to do something reasonable about it.Maunus 08:11, 14 August 2006 (UTC)[reply]
adding images and restructuring
I added two images: a tree diagram of the mayan language family and a map of their distribution. I pulled out the list of Mayan languages and I will instead make a list at the end of the article with links to the respective Ethnologue ISO-codes and wikilinks to their articles.
I'Maunus 11:46, 28 August 2006 (UTC)ve inserted the material again in the form of an infobox of the mayan language family.[reply]
The Chuj branch is missing from your infobox. Also I notice that Jakaltek dropped out in your tree diagram, which is probably justifiable linguistically (very close to Q'anjob'al) but contrary to ALMG - I'd support you but it's worth mention. Finally, I like your linguistic features edit, it is clearly less idiosyncratic than my own initial attempt, but I think that a few of the things which you cut (effects on Guatemalan Spanish, Lenkersdorf's Sapir-Worfean thesis about Tojolabal, and to a much lesser extent the Lakoff reference), while not necessarily of strictly linguistic interest, are of interest to a general encyclopedic user. Would you object to my putting them back in, conforming of course to your improved format? --Homunq 17:46, 28 August 2006 (UTC)[reply]
Nope, go ahead. It was a table syntax error that made the Chujean-Qanjobalan branch fail to show. Poptí is another name for Jakaltek, which is used by Nora C England upon whose book I have based the diagram (and she is a big supporter of ALMG). The lakoff stuff I don't really find relevant because 1. his book is not about the maya and he is not a specialist in mayan languages, and other scientist deal much better with the spatial description stuff in mayan languages (there is a lot of literature references about this in the Mesoamerican Linguistic Area article.) and also to me it is not as much the embodiment part that is interesting but the way in which Mayan languages (and mesoamerican languages in general) use them grammatically: this is the part about relational nouns derived from bodyparts. The lenkersdorf experiment stuff I didn't understand the way it was described, but seemed like a very simple way to connect ergative grammar to the linguistic relativity hypothesis. I think if it should go any where it should be in the article Sapir-Whorf hypothesis in the experimental support part. The effects on Guatemalan spanish I also don't think are documented the very same features are common in rural central mexican spanish and while some linguits argue that here it is due to influence from Nahuatl (which has the sdsame constructin as Maya) it is not really possible to unequivacally attribute it to substrate influence (the same constructions are found in European spanish dialects) If you do chose to put it back in though I will not object, although I may reword it. Maunus 21:04, 28 August 2006 (UTC)[reply]
Lakoff: OK, just add a bullet for semantic calques. Influence on Spanish: I have definitely heard this construction more in Guatemala and Chiapas than in Milpas Altas, DF (though the latter was only the outer orbit for me when I was in the DF); I think this should go somewhere but will defer to you on whether here or MLA. Lenkersdorf: I was trying to simplify a whole book of argumentation into a quick paragraph, of course it comes across as simple. How about I put it in Sapir-Worf with here "(This feature has been used to advance the Sapir-Worf hypothesis in relation to the Tojolabal language.)" Honestly, Lenkersdorf's thesis doesn't really rise to the level of experimental support - he has deep experience and several arguments but all of them are just suggestive, not conclusive.--Homunq 18:48, 29 August 2006 (UTC)[reply]
Sounds fine to me.Maunus 20:20, 4 September 2006 (UTC)[reply]
Proto-mayan area?
Was there ever really a single language spoken from Yucatan to Pacific? Seems more likely that it started from a smaller area and spread (as it simultaneously lost unity) through conquest, association with effective cultural practices, and/or religion/literature. What do linguists think, this issue is obviously true for a lotta "proto" languages? Meanwhile, I'm adding "...the ancestor of languages now...", though I worry I'm bordering on original research. --Homunq 06:08, 9 November 2006 (UTC)[reply]
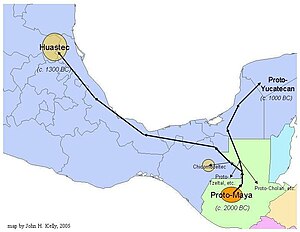
It is not really true. The Protomayan homeland is thought to have been in the the northern highlands or southern lowlands of Guatemala, (around the rio pasion and usumacinta) this is where the greatest linbnguistic diversity is today and sos looks to bee the center of expansion. Look at the article on the Huastecs - which is well referenced and has this nice map: , maybe we should include it. Fig. 1. Approximate routes and dates of the proto-Huastec and other Maya-speaking groupsMaunus 08:40, 9 November 2006 (UTC)[reply]
Great map, I stuck it in but I had to move the other boxes around not to clutter things up, see if you like the result. --Homunq 04:59, 10 November 2006 (UTC)[reply]
GA nomination
I have nominated this article for Good Article status. I hope you will all help to fix it up when the comments and suggestions start coming. Maunus 12:11, 30 November 2006 (UTC)[reply]
I have decided to de nominate and instead have it peer reviewed that gives us more time to fix it up according to the reviewers comments. Maunus 21:58, 30 November 2006 (UTC)[reply]
Distribution map, genealogy tree and other minor criticisms
The size of the words should correlate to the populations - the worst offender is Itza', a probably extinct language which is writ large.--200.6.247.89 00:50, 2 December 2006 (UTC)[reply]
I've made a note that letter sizes do not reflect spaker populations. (in fact the small lettes are just used for languages with long names in the highlands were they are spoken s close to eachother)Maunus 10:50, 3 December 2006 (UTC)[reply]
Also in the genealogy tree figure, Q'eqchi' is misspelled, and Achi appears in parentheses after Sipakapense and Sakapultek for some reason. If we accept the ALMG position, then all three are separate languages. If we go with the OKMA view, then Achi is a dialect of K'iche', but S and S are still languages. — MikeG(talk) 04:23, 2 December 2006 (UTC)[reply]
Fixed the geanalogy tree. Maunus 10:50, 3 December 2006 (UTC)[reply]
Oh no there's one more mistake. The eastern and western branches are switched - If someone can take care of it I would appreciate it otherwise I'll do it later.Maunus 20:19, 4 December 2006 (UTC)[reply]
While we're on the subject of errors, I think both the 4 million speakers and the 5 non-Guatemalan Mexican languages are low. I count 8 Mexican languages (Yukatek Maya, Chol, Tojolabal, Tzotzil, Tzeltal, Wastec, Aguacateco, Chontal de Tabasco). Also, adding up just the Mexican speakers from http://es.wikipedia.org/wiki/Lenguas_de_M%C3%A9xico, I get 2051675; taking 40% of Guatemala (based on http://es.wikipedia.org/wiki/Demograf%C3%ADa_de_Guatemala) gives 5055975; and 10% of Belize (http://es.wikipedia.org/wiki/Belice) gives 28107, totalling 7135758. Those last two numbers are ethnic and not linguistic, but since language is the primary ethnic identifier in the region the estimate is decent. I'm conservatively going up to "over 6 million speakers" and 8 Mexican languages but please check me. --200.6.247.89 13:12, 2 December 2006 (UTC) ps. If we could attach speaker numbers to all the languages, I'd say this article would be ready for GA status or better.[reply]
Looking at the "sounds" section: it generally only includes sounds that are in ALL mayan languages, but then it also adds the long vowels. On that basis, we should include other sounds (such as the "sixth vowel" written ë) that are in many-but-not-all the languages. Also: if we want to include a picture for the heiroglyphs section, I could easily upload (from any one of a number of sources) a sample from the Dresden codex, from folio 7 or something, one of the list of figures with 4 blocks and 2 numbers above them... I think that would be a clear fair use but do others agree? Certainly it would make a nice counterpoint to the petroglyphic figures elsewhere. --200.6.247.89 21:45, 2 December 2006 (UTC)[reply]
I put in the stucco glyphs used on the Maya script article for now. Scans of the dresden codex will be greatly appreciated. There is no copyright on photographic representations of the codices, only on drawings (as far as I know).Maunus 20:18, 4 December 2006 (UTC)[reply]
Wow, thanks, Maunus, that's great (going from "sounds" to "phonological overview"). The one thing that's been lost is the ALMG orthography for all those sounds (though obviously nonexistent for the three proto-mayan-only sounds) - I can make a good stab at it if you don't but you're obviously the expert so I'll give you a chance to do it. --200.6.247.89 14:44, 4 December 2006 (UTC)[reply]
I placed the AMLG overview in the final section on mesoamerican writing systems, I am not sure if it reflects the most up to date orthography though and I would be happy if you cheked it.Maunus 16:04, 4 December 2006 (UTC)[reply]
Things are coming along. Can you please add ALMG "q" and "b" (as opposed to "b'")? Again, I'll take a stab if you don't, but I'm the dilettante here. Also, I know that h and y need footnotes (H also used silently to prevent dipthongs, and Y pronounciation varies, at least in Eastern Kaqchikel, between word-final and word-internal - I think it has two valid pronounciations.) And I've heard that the proper IPA for "glotallized consonants" is actually a "creaky" modifier on the following vowel... should this go in a footnote too? I'll check all your work over later from my sources but I'd rather not innovate on the page, currently I'm just watching you.--200.6.254.170 19:25, 6 December 2006 (UTC)[reply]
But mayan consonants are ejectives and according to the version of the IPA handbook I am using (1999) they are shown with a ['].I am not an expert on ALMG - the only book I have using that orthography is Englands 1998 book - changes after that I don't know nor do I know all the variants for different languages, so please go ahead and boldly add anything you think is wrong, missing or could be expressed better. You don't seem a dilletante at all. (have you considered registering an account?)Maunus 22:33, 6 December 2006 (UTC)[reply]
Mayance in the infobox
Should we have the term "Mayance languages" appearing in the infobox? I had thought that this term was not widely used these days...--cjllw | TALK 02:51, 5 December 2006 (UTC)[reply]
Check out Indo-European languages which has "Indo-Germanic" in the corresponding place. I think that means that that slot is reserved for less-preferred terms, so this is fine. (ps. Also note that that page gives priority to its "category template" over its "infobox"... given the flow of the text, from general-interest to detailed, I think that may be the better choice.)--200.6.254.170 20:35, 6 December 2006 (UTC)[reply]
Tables of soundchanges
I am unsure whether the scematic overview table of soundrules from ProtoMayan to modern languagegroups is too big or not necessary. I thouhgt it would be a good graphical way of showing the soundchanges that are the basis for the classification of he languages. It may however be too linguistic (the soundchange formula forexample) or too obscure or too much a repetition of the preceding prose section. I would like comments.Maunus 19:19, 7 December 2006 (UTC)[reply]
I think everything after the disappeared consonants should be moved to proto-mayan (which, as I have suggested, should be merged with Classic mayan into "Ancient mayan languages", but that's a separate issue). It's interesting for me, but probably doesn't belong here.
As for the table (once moved to proto-mayan), as it is, it doesn't add much... but if you put separated the modern language branches each to their own column, then filled in the unchanged sound in the extra columns, and colored the changed sounds, it would start to have some punch. Up to you whether you feel like spending the effort. --Homunq 20:15, 7 December 2006 (UTC)[reply]
I do think it is important to show the linguistic basis on which the classification of mayan languages as a language family rests - and that is that they can be explained as having evolved from a proto language through a series of soundchanges. If what you suggest is adding the entire phoneme inventories of all the modern languages with a difference in colour showing the changed versus unchanged phonemes I don't find that a good idea. The idea is to show that the basis for classifying the subgroups of the mayan languages is a number of shared innovations between languages. This entails showing which phonemes changed into what under which conditions and in which language groups. I don't think the way you suggest would do that well. I must admit that I don't understad your idea completely. Maybe you could begin the work here on the talk page to show what you mean more precisely? If other editors feel that the comparative phonological framework doesn't belong on this page but on proto-mayan we'll move it there though, no problem.Maunus 21:01, 7 December 2006 (UTC)[reply]
I've done some changes here taking your ideas into account. I think it is better shown with actual cognate words because then we don't run the risk of providing false information. The colours can be changed easily to fit with madmans maps.What do you think?Maunus 11:45, 8 December 2006 (UTC)[reply]
I take it that that means acceptable. Feel free to improve or suggest though.Maunus 21:03, 8 December 2006 (UTC)[reply]
Reworking maps
I will be reworking the genealogy tree and then the map to reflect the changes in the article and errors, to provide some color coding in an attempt to help the average reader mentally keep track of these unusual words, and to provide some "punch" to the article. This should take me a couple of weeks. Once published, I will take feedback and can easily edit both/either. Madman 21:42, 7 December 2006 (UTC)[reply]
Sorry for my delay on these. I've been tied up on non-Wikipedia matters. I expect to complete at least a first attempt at the chart by Friday evening and will work on the map next week. Thanks, Madman 15:10, 13 December 2006 (UTC)[reply]
Grammar section
I have begun building a grammar section from scratch as I go along i will incorporte and explain the current factbites into the prose section - but meanwhile I have put them in a subsection called "further grammatical comments" this section will be eliminated when I am done. I am downplaying Carlos Lenkesdorf because I am planning a section called linguistic studies which will deal with Lenkersdorfs and John A Lucys studies about Mayan languages and the Sapir/whorf hypothesisMaunus 15:21, 10 December 2006 (UTC)[reply]
Refs and citations
In tidying up the references and citations, we have an entry for two of the vols in the Handbook of Middle American Indians series. Were any specific papers in these vols used (and which could therefore be more directly cited)? I have a copy of Vol 5 (Linguistics) but not Vol 7 {Ethnology), and I'm unable to make out what the LCC F 1434, H 3, LAC attribution affixed may be - is this some library catalogue ref? --cjllw | TALK 08:49, 8 December 2006 (UTC)[reply]
Article length
The article is growing long. If you can think of ways to trim it, make language or sections more precise or have ideas for splitting out some topics in smaller articles I'll be glad to hear suggestions, or you can go ahead and we'll see how it turns out. I think I am currently too close to the article to propose splits myself: I think all of what I have written is important for an adequate coverage of a broad topic - but that doesn't mean that I can't be convinced otherwise. I am aware that there are many examples, I would like to have even more since they are the best way of conveying condensed information, but they do take up a lot of space and can never go without explicit comments on what is being examplified.Maunus 11:28, 12 December 2006 (UTC)[reply]
Yipes, it really does feel like information overload here. It gets heavy on jargon in pretty much all of the sections. A few suggestions for improvement
try to make at least section-heads as meaningful and jargon-free as possible. For instance, rather than saying "morphosyntactic alignment", say "Treatment of subjects and objects".
Honestly, the Lenkersdorf stuff is useful here: he suggests that transitive verbs are cognitively "read" backwards, as in "you guys experienced his/her taking". His whole thesis on Sapir-Worf may be hyperbole, but at least it gives you some way to understand what is being said without relying on the bloodless formality of "set A" and "set B". Is there some way to include such Lenkersdorf-style glosses as "understanding aids" without giving them too much weight as "this is really what is being said"?
Definitely we need to start to split some of the heavier stuff out into sub-articles. I understand that the new grammar section has a lot of good new info but the quick list of features was much less daunting. As I see it, there is no "natural" article-that-people-would-ever-search-for, but there are clear sections for geneology and linguistics which could go in Mayan Languages (x)...
As work towards splitting off the sections, a quick, readable, header section/paragraph each for grammar and phonology - the geneaology is well-covered by the tree.
Unrelated - I'd really like to see the ALMG side-by-side with IPA, when both exist solo the distinction between [x] and 'x' is confusing to say the least. In fact, if we consistently put ALMG first, we can get away with that only in some cases, because the IPA brackets cue it as secondary.
...Well, as you can see, I'm a little lost myself, but count this as a vote that there has to be a simpler way to build up to the heavy stuff here. --Homunq 01:06, 13 December 2006 (UTC)[reply]
I disagree very much with your idea of changing established linguistic terminology into laymans terms - "treatment of subject and object" simply isn't informative and is in fact wildly incorrect linguistically (subject and object are not useful categories for describiing many phenomena of non accusative languages). I have read a bit up on Carlos Lenkersdorf and the reason I hesitate to include him here is firstly that his ideas about morphosyntactical alignment are controversial and that their conclusions are of a more philosophical than grammatical nature. Linguistically speaking they just don't hold water and none of the standard literature on ergativity in mayan as much as mentions his ideas. Standard literatre do use the terminology of set A and B which serve to not confuse the form level of language with the meaning level: this is important because in these cases the same prefix forms are used to express different meanings in different contexts (Set B expresses both the ergative case (agent of transitive verb) and possessor of a noun for example). I wouldn't mind including Lenkersdorf in a section on Mayan languages and studies of linguistic relativity though - there are enough studies made about mayan to make an article on that topic alone. In the choice between IPA and ALMG in examples IPA must be most important because that is the accepted standard and the one we can expect our readers to know beforehand. Maybe you are right that the Grammar and phonology sections could be summarized and moved to different pages. Maybe we could make a Mayan languages (typological overview) article like the ones A.R.King has made for Miskito and PipilMaunus 04:52, 13 December 2006 (UTC)[reply]
First off, IANAL (I am not a linguist), so I clearly defer to you on inaccuracy. But I really would like to move away from jargon here, and am searching for ways to do it. Compare French language - our audience should be about the same, high-school non-linguists. As it stands, the article is tough going for me, a non-linguist who has been exposed to all the concepts it contains. It is in that context that I bring in Lenkersdorf, and in that context that I wish to present him. Something like: "Readings in the style of Carlos Lenkersdorf (who originated them in the context of Tojolabal) are not widely accepted linguistically, but are presented here in order to help distinguish the usage of sets A and B."... Personally, I'm fully aware that he's an anthropologist and NOT a lingust, and linguistically he goes way out on a limb to say the least; but his readings have been a very invaluable tool to me as I learn Kaqchikel, and I have seen them help as I have shared them with my teacher and fellow students, too. (My teacher, a native speaker, found them neither obvious nor ridiculous from an intuitive standpoint, for what it's worth.) At the very least, treat all uses of A and B (possessives, relational nouns, verbs, and set A with adjectives-used-as-intransitive-verbs) together, rather than peppering them around in sections based on extramayan linguistic criteria.
As to IPA and ALMG, again, I refer to French language, which has standard orthography with or without IPA, but never IPA alone. I see no reason to assume that the average person with an interest in this article will have had more exposure to IPA than to latinized Mayan, nor any reason to want to teach them IPA here.
As to splitting the article, I think we should first edit it here, but with an eye to splitting off the heavier linguistic stuff (both phonological and grammatical) later - and perhaps we'll find that after writing good summary sections no split is needed. I'm waiting till we reach some consensus here to start that, though.--201.216.149.47 16:37, 13 December 2006 (UTC)[reply]
I don't really know who else might build consensus with us - there aren't so many interested parties. I'll try to give some if you do - let's do it that way. If you start editing your suggestions in and trimming the language I'll check it over and we'll discuss any controversies here in good spirit like we usually do. How does that strike you? (as for the ALMG I am not at all against putting it next to IPA as in French language - but my sourcs don't present ALMG so I would have to venture the spellings myself at risk of error - something that I would rather not. I f you feel confident in ALMG spellings please provide them where ever you deem necessary)Maunus 16:44, 13 December 2006 (UTC)[reply]
I can add the ALMG orthography when it's called for in most cases (and there are still some corrections/additions to be made in what's been said about it already, especially for K'iche'), but we have to remember that it will only work for the Guatemalan languages. The Mexican languages have their own standards, which sometimes deviate from ALMG conventions (for example, the use of b for b' ). That said, it would make sense to include standard orthography alongside IPA, whatever the language. — MikeG(talk) 17:47, 13 December 2006 (UTC)[reply]
Table: Uses of sets A and B
Homunq, first I didn't understand your table at all but then I understood it - and thought that it was just the layout that made it complicated. I decided to split it up into two separate tables. I think it works better this way - I hope you see my point. I have provided the linguistically acceptable definition of ergativity and made a more predagogical prose explanation of Lenkersdorfs line of arguments - I hope I understand them well enough, otherwise correct it. But I think it is important to have a prose explanation of the tables and lenkersdorfs way of seeing it if it is going to help the linguistically unprepared reader and make any sense to the linguistically prepared one as well. I have made minor corrections to language. At first I found your edits horrible and destructive to "my article" but reading them a couple of times I understood that it actually does make an interesting and welcome addition. I hope my changes to them are acceptable to you.Maunus 21:32, 14 December 2006 (UTC)[reply]
Thanks - I think :). Your changes are a definite improvement. I understand that that was a bit of a mess - it was a first draft, and I couldn't even see the table as I edited it because I was doing it offline. I like your solution of repeating the transitive verb line. I still plan to fix up some loose ends I left but I think this is coming together. Just a point of curiosity: do you know if in Basque, set B is possessive?--Homunq 04:58, 15 December 2006 (UTC)[reply]
Basque doesn't mark ergativity by crossreferencing the pronominal markers like Mayan and Mixe-Zoquean do basque uses a case system marking nouns for ergative or absolutive case I don't know if they use ergative for possessors that aren't agents or if they just use genitive case on the possessed noun. (I do know that Greenlandic which is also ergative does use the ergative case to mark possessors)Maunus 05:46, 15 December 2006 (UTC)[reply]
Starting to really pick nits
The article claims that the structure is CV or CVC and consonant clusters only happen across syllable boundaries. My experience in practice is that there are occasionally hard-to-pronounce series of three or more (?) consonants, usually involving one-consonant affixes such as "x-" (completive). My uninformed intuition says that the sentence should read "C, CV, or CVC". Or does the "x-" have a dropped vowel in there? --Homunq 22:39, 15 December 2006 (UTC)[reply]
What I have written is not entirely true, it was probably true for the protolanguage but not at all for modern mayan languages (i do believe most of the clusters arise originally from dropped vowels). I will try to find a better description of syllable structure in mayan in general. Your concern is valid.Maunus 06:03, 16 December 2006 (UTC)[reply]