
Unit circles of different
p norms in two dimensions
In mathematics , the p -norms are a class of vector norms that are defined for real numbers . Important special cases are the sum norm , the Euclidean norm and as a limit value for the maximum norm . All norms are equivalent to each other , monotonically decreasing for increasing and satisfy the Minkowski inequality as well as the Hölder inequality . The sets of constant -norm ( unit spheres ) generally have the form of superellipsoids or subellipsoids. The norms form the basic building block for norms of further mathematical objects , such as sequences , functions , matrices and operators .





definition
The norm of a real or complex vector with or is for real by





defined, where is the amount of the component . It is irrelevant for the definition whether it is a row or a column vector . In this case , all norms correspond to the norm of the absolute value of a real or complex number.




The set of vectors with -norm one is called the unit sphere of the norm, whereby only in this case the unit sphere actually corresponds to the sphere known from geometry . The unit spheres of norms are generally in two dimensions in the form of Super ellipses or Subellipsen and in three and higher dimensions the form of Superellipsoiden or Subellipsoiden.



Important special cases
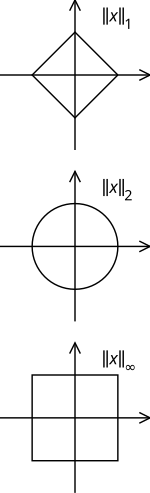
The unit circles of the sum norm, the Euclidean norm and the maximum norm in two dimensions
Sum norm
The 1 norm is also called sum norm or sum norm for short and is through

Are defined. It corresponds to the sum of the amounts of the components of the vector. The unit sphere of the real sum norm has the shape of a square in two dimensions, the shape of an octahedron in three dimensions and the shape of a cross polytope in general dimensions .
Euclidean norm
The 2 norm is the Euclidean norm and through

Are defined. It corresponds to the root of the sum of the squares of the absolute values of the components of the vector. The unit sphere of the real Euclidean norm in two dimensions has the shape of a circle , in three dimensions the shape of a spherical surface and in general dimensions the shape of a sphere . The Euclidean norm describes the illustrative length of a vector in a plane or in space in two and three dimensions .
Maximum norm
The ∞ norm (infinite norm) is obtained for the limit value , which is often also counted among the norms. It is also called the maximum norm or Chebyshev norm and is through

Are defined. It therefore corresponds to the amount of the largest component of the vector. The unit sphere of the real maximum norm has the shape of a square in two dimensions, the shape of a cube in three dimensions and the shape of a hypercube in general dimensions .
That the maximum norm actually arises as a limit value of the norms for follows for from

-
 ,
,
since applies to the sum and thus the limit of for is equal to one. The lower bound of is assumed for a vector whose components are all but one equal to zero, and the upper bound for a vector whose components all have the same amount. By omitting the limit, it can be seen that the maximum norm is never greater than the other norms.

![\ sqrt [p] {S}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bce901f640328d70379042645fe1bed7f6e8e811)


Examples
Real vector
The 1, 2, 3, and ∞ norms of the real vector are each given as

![{\ displaystyle {\ begin {aligned} \ | x \ | _ {1} \, \, & = | 3 | + | {-2} | + | 6 | = 11 \\\ | x \ | _ {2 } \, \, & = {\ sqrt {| 3 | ^ {2} + | {-2} | ^ {2} + | 6 | ^ {2}}} = {\ sqrt {49}} = 7 \ \\ | x \ | _ {3} \, \, & = {\ sqrt [{3}] {| 3 | ^ {3} + | {-2} | ^ {3} + | 6 | ^ {3 }}} = {\ sqrt [{3}] {251}} \ approx 6 {,} 308 \\\ | x \ | _ {\ infty} & = \ max \ {| 3 |, | {-2} |, | 6 | \} = 6 \ end {aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4630d4672323bea49d3e9d79da2c5e839aca4f54)
Complex vector
The 1, 2, 3 and ∞ norms of the complex vector are each given as

![{\ displaystyle {\ begin {aligned} \ | x \ | _ {1} \, \, & = | 3-4i | + | {-2i} | = 5 + 2 = 7 \\\ | x \ | _ {2} \, \, & = {\ sqrt {| 3-4i | ^ {2} + | {-2i} | ^ {2}}} = {\ sqrt {5 ^ {2} + 2 ^ {2 }}} = {\ sqrt {29}} \ approx 5 {,} 385 \\\ | x \ | _ {3} \, \, & = {\ sqrt [{3}] {| 3-4i | ^ {3} + | {-2i} | ^ {3}}} = {\ sqrt [{3}] {5 ^ {3} + 2 ^ {3}}} = {\ sqrt [{3}] {133 }} \ approx 5 {,} 104 \\\ | x \ | _ {\ infty} & = \ max \ {| 3-4i |, | {-2i} | \} = \ max \ {5.2 \ } = 5 \ end {aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d2503130f1075bf829f52b295f4915ca884af689)
properties
Norm axioms
All norms including the maximum norm fulfill the three norm axioms definiteness , absolute homogeneity and subadditivity . The definiteness follows from the positivity of the power functions for positive arguments and the uniqueness of the zero at the point with which


applies. The homogeneity follows from the homogeneity of the amount standard on
-
 .
.
The triangle inequality for norms is precisely the Minkowski inequality
-
 ,
,
which in turn is based on the following Hölder inequality .
Holder's inequality
If exponents are conjugate to one another, that is, by convention , then the corresponding -norms
apply


-
 ,
,
which in turn follows from Young's inequality . In this case , the Hölder inequality corresponds to the Cauchy-Schwarz inequality .

monotony
The norms are monotonically decreasing for a fixed vector and monotonically decreasing for increasing ones , that is, for applies

-
 .
.
This property follows for and from the monotony of the power functions for through


![z \ in [0.1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/f20fead0085cbd4473680e23f8353908a40ab312)
-
 ,
,
because the fraction can only have a value between zero and one. For a given vector the sum norm is the largest and the maximum norm the smallest norm (see also the examples above). Equality across all norms applies if and only if the vector has at most one component not equal to zero, for example the zero vector or the -th unit vector . It is synonymous with monotony that the uniform spheres of the norms contain each other for growing , that is, for applies


-
 .
.
equivalence
All norms are equivalent to each other , that is, to any pair of norms with there are two positive constants and , so for all





applies. The lower constant is always equal to one due to the monotony. The upper constant depends on the selected norms and is assumed for a vector with components of the same magnitude ( e.g. the one vector ). Namely, the Hölder inequality results in the choice of the Hölder exponents and for


-
 .
.
With the convention in the exponent, this estimate also remains valid for or . The equivalence constant of the standards is summarized again in the following table:



|
|
 -Standard -Standard
|
 -Standard -Standard
|
 -Standard -Standard
|
|
-Standard
|
|
 |
|
|
-Standard
|
|
 |

|
|
-Standard
|
|
|
|
For example, the entry in the first row and second column is for as


to read. The norms therefore differ for a fixed vector by a maximum of the factor . The optimal constants in such norm estimates lead to the calculation of distances in the Minkowski compact .
Absoluteness
All norms including the maximum norm are absolutely, that is, for all vectors applies

-
 ,
,
where represents the component-wise magnitude of a vector.

Component-wise monotony
Because of the absoluteness, the norms for fixed are monotonically increasing with the magnitude of each component of a vector , that is, it holds


for everyone with for . For even applies strict monotony




for everyone with for and for at least one .


Generalizations
Case p <1

The unit circle of the (2/3) -norm, a quasi-norm, is an
astroid in two dimensions .
The figure defined
for

is not a norm, because the resulting unit sphere is no longer convex and the triangle inequality is violated. These maps are only quasinorms , where the triangle inequality is replaced by the weaker inequality for a real constant .


ℓ p norms
The norms are the generalization of the norms to sequence spaces , where only the finite sum is replaced by an infinite sum. The norm in an amount as th power summable sequence is then for given as


-
 .
.
For the limit value there is the space of limited consequences with the supremum norm .
L p norms
Furthermore, the norms can be generalized to function spaces, which happens in two steps. First, the -norms of a -th power on a set of Lebesgue integrable functions are for as



-
 ,
,
defined, whereas in comparison to the norms only the sum was replaced by an integral. These norms are initially only semi-norms , since not only the null function , but also all functions that differ from the null function only in a set with Lebesgue measure zero, are integrated to zero. Therefore one considers here the set of equivalence classes of functions , which are almost everywhere the same, and obtains the norms
in these spaces![[f] \ in L ^ {p} (\ Omega)](https://wikimedia.org/api/rest_v1/media/math/render/svg/821ff5332b92210754f0b608d04b35aa7ce334a5)

-
![\ | \, [f] \, \ | _ {L ^ {p} (\ Omega)} = \ | f \ | _ {{\ mathcal {L}} ^ {p} (\ Omega)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/966f36cc30607ca13e2fb30c25894acb5dff9495) .
.
For the limit value, this results in the space of the essentially restricted functions with the essential supreme norm . The norms and spaces can also be generalized from the Lebesgue measure to general measures and from real or complex-valued functions to Banach space-valued functions by replacing the absolute value with the corresponding norm.
Matrix norms
By simply viewing a matrix as a correspondingly long vector , matrix norms can be defined directly via the norms. Examples of such matrix norms are the Frobenius norm based on the 2 norm and the overall norm based on the ∞ norm . Matrix norms, however, are mostly induced by a norm as an induced matrix norm

-
 .
.
derived. Examples of matrix norms defined in this way are the column total norm based on the 1 norm , the spectral norm based on the 2 norm and the row total norm based on the ∞ norm . Another possibility to define matrix norms is to consider the norm of the vector of the singular values of the matrix, as is the case with the shadow norms . Norms for more general linear operators can also be defined in an analogous manner .
literature
- Hans Wilhelm Alt: Linear Functional Analysis: An Application-Oriented Introduction . 5th edition. Springer-Verlag, 2008, ISBN 3-540-34186-2 .
-
Gene Golub , Charles van Loan: Matrix Computations . 3. Edition. Johns Hopkins University Press, 1996, ISBN 978-0-8018-5414-9 .
- Roger Horn, Charles R. Johnson: Matrix Analysis . Cambridge University Press, 1990, ISBN 978-0-521-38632-6 .
- Hans Rudolf Schwarz, Norbert Köckler: Numerical Mathematics . 8th edition. Vieweg & Teubner, 2011, ISBN 978-3-8348-1551-4 .
Web links
Individual evidence
-
^ Friedrich L. Bauer , Josef Stoer , Christoph Witzgall: Absolute and monotonic norms . In: Numerical Mathematics . tape 3 , no. 1 , 1961, pp. 257-264 .
-
↑ Matthias Ehrgott: Multicriteria Optimization . 2nd Edition. Springer, 2005, p. 111-113 .



