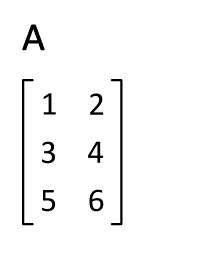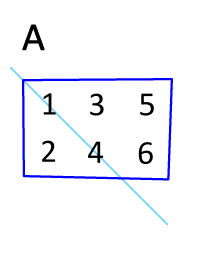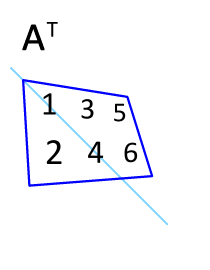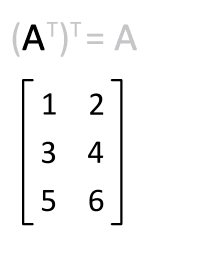
Animation for transposing a matrix
In mathematics , the transposed matrix , mirrored matrix or inverted matrix is the matrix that is created by swapping the roles of rows and columns in a given matrix. The first row of the transposed matrix corresponds to the first column of the output matrix, the second row to the second column and so on. The transposed matrix is clearly created by mirroring the output matrix on its main diagonal . The process of converting a matrix into its transposed matrix is called transposing , transposing, or overturning the matrix.
The transposition mapping that assigns its transpose to a matrix is always bijective , linear and self-inverse . With regard to the matrix addition it provides a isomorphism is, with respect to the matrix multiplication , however, a Antiisomorphismus , that is, the order in the multiplication of matrices is reversed by transposition. Many parameters of matrices, such as track , rank , determinant and eigenvalues , are retained under transposition.
In linear algebra , the transposed matrix is used, among other things, to characterize special classes of matrices. The transposed matrix is also the mapping matrix of the dual mapping of a linear mapping between two finite-dimensional vector spaces with respect to the respective dual bases . Furthermore, it is also the mapping matrix of the adjoint mapping between two finite-dimensional real scalar product spaces with respect to the respective orthonormal bases . The concept of transposing a matrix was introduced in 1858 by the British mathematician Arthur Cayley .
definition
If there is a field (in practice mostly the real or complex numbers ), then it is related to a given matrix

transposed matrix defined as
-
 .
.
The transposed matrix results from the fact that the roles of rows and columns of the output matrix are reversed. Clearly, the transposed matrix by arises mirroring the output matrix in its main diagonal with . Occasionally the transposed matrix is also notated by , or .







Examples
Transposing a matrix (a row vector ) results in a matrix (a column vector ) and vice versa:



A square matrix retains its size through transposition, but all entries are mirrored on the main diagonal:

Transposing a matrix creates a matrix in which the first row corresponds to the first column of the output matrix and the second row corresponds to the second column of the output matrix:



properties
total
The following applies to the transpose of the sum of two matrices of the same size

-
 .
.
In general, the sum of matrices of the same size results in


-
 .
.
The transpose of a sum of matrices is therefore equal to the sum of the transposed.
Scalar multiplication
The following applies to
the transpose of the product of a matrix with a scalar

-
 .
.
The transpose of the product of a matrix with a scalar is therefore equal to the product of the scalar with the transposed matrix.
Double transposition
The following applies to
the transpose of the transpose of a matrix
-
 .
.
Therefore, by double transposition, the output matrix always results again.
product
The following applies to
the transpose of the product of a matrix with a matrix
-
 .
.
In general, the product of dies of the appropriate size
results
-
 .
.
The transpose of a product of matrices is therefore equal to the product of the transposed, but in reverse order.
Inverse
The transpose of a regular matrix is also regular. The following applies to the transpose of the inverse of a regular matrix

-
 ,
,
because with the identity matrix results


and therefore the inverse matrix is too . The transpose of the inverse matrix is therefore equal to the inverse of the transposed matrix. This matrix is sometimes also referred to as.


Exponential and logarithm
The following applies
for the matrix exponential of the transpose of a real or complex square matrix
-
 .
.
Correspondingly, the transpose of a regular real or complex matrix
applies to the matrix logarithm
-
 .
.
Transposition mapping
The figure
-
 ,
,
which assigns its transpose to a matrix is called a transposition mapping. Due to the above laws, the transposition mapping has the following properties:
Block matrices
The transpose of a block matrix with row and column partitions is through



given. It is created by mirroring all blocks on the main diagonal and then transposing each block.
Parameters
rank
For a matrix , the rank of the transposed matrix is the same as that of the output matrix, that is
-
 .
.
The image of the figure will be supported by the column vectors of clamped while the image of the image of the row vectors of spanned. The dimensions of these two pictures always match.


track
For a square matrix , the trace (the sum of the main diagonal elements ) of the transposed matrix is equal to the trace of the output matrix, that is
-
 ,
,
because the diagonal elements of the transposed matrix agree with those of the output matrix.
Determinant
For a square matrix , the determinant of the transposed matrix is equal to the determinant of the output matrix, that is
-
 .
.
This follows from the Leibniz formula for determinants about
-
 ,
,
where the sum runs over all permutations of the symmetric group and denotes the sign of the permutation .



spectrum
For a square matrix , due to the invariance of the determinant under transposition, the characteristic polynomial of the transposed matrix is also identical to that of the output matrix, because
-
 .
.
Therefore, the vote eigenvalues of the transposed matrix with which the output matrix match, that is, for the respective spectra applies
-
 .
.
However, the eigenvectors and eigenspaces do not have to match.
similarity
Every square matrix is similar to its transpose, that is, there is a regular matrix such that


applies. The matrix can even be chosen symmetrically . From this it follows, among other things, that a square matrix and its transpose have the same minimal polynomial and, provided that its characteristic polynomial is completely divided into linear factors , also have the same Jordanian normal form .

Norms
The Euclidean norm of a real vector is through


given. The following applies to
the Frobenius norm and the spectral norm of the transpose of a real or complex matrix
-
 and .
and .
The row sum norm and the column sum norm of the transpose and the output matrix are related as follows:
-
 and .
and .
Scalar products
The standard scalar product of two real vectors is through



given. With respect to the standard scalar product, a real matrix and its transpose have the displacement property

for all vectors and on. The standard scalar product im is on the left and the standard scalar product im is on the right . For the Frobenius scalar product of two matrices we have




-
 ,
,
because matrices under the track can be interchanged cyclically .
use
Special matrices
The transposed matrix is used in a number of definitions in linear algebra:
- A symmetric matrix is a square matrix that is equal to its transpose, that is .

- A skew-symmetric matrix is a square matrix that is equal to the negative of its transpose, that is .

- A Hermitian matrix is a complex square matrix whose transpose is equal to its conjugate , that is .

- A skewed Hermitian matrix is a complex square matrix whose transpose is equal to the negative of its conjugate, that is .

- An orthogonal matrix is a square matrix whose transpose is equal to its inverse, that is .

- A (real) normal matrix is a real square matrix that commutes with its transpose , that is .

- For any real matrix, the two Gram matrices and are always symmetric and positive semidefinite .


- The dyadic product of two vectors and gives the matrix .



Bilinear forms
If and are finite-dimensional vector spaces over the body , then every bilinear form can be defined by the representation matrix after choosing a basis for and a basis for





describe. If and are the coordinate vectors of two vectors and , then the value of the bilinear form results as




-
 .
.
If now and further bases are each of and , then applies to the corresponding representation matrix


-
 ,
,
where the base change matrix is in and the base change matrix is in . Two square matrices are therefore congruent to one another precisely then , so it is true




with a regular matrix if they represent the same bilinear form with respect to possibly different bases.

Dual images
If again and are finite-dimensional vector spaces over the body with associated dual spaces and , then the dual mapping associated with a given linear map becomes through





characterized for all . If there is now a basis for and a basis for with associated dual bases and , then the relationship
holds for the mapping matrices from and from






-
 .
.
The mapping matrix of the dual mapping with respect to the dual bases is accordingly precisely the transpose of the mapping matrix of the primal mapping with respect to the primal bases. In physics , this concept is used for covariant and contravariant vector quantities.
Adjoint mappings
If now and are finite-dimensional real scalar product spaces , then the adjoint mapping belonging to a given linear mapping becomes through the relation


for all and characterized. Furthermore, if an orthonormal basis of , an orthonormal basis of and the mapping matrix of with respect to these bases, then the mapping matrix of with respect to these bases is even


-
.
In real matrices thus leading to a given matrix is adjoint matrix just the transposed matrix, ie . In functional analysis , this concept is generalized to adjoint operators between infinite-dimensional Hilbert spaces.

Permutations
The transposed matrix also defines special permutations . If the numbers from to are written row by row into a matrix and then read off again column by column (which corresponds exactly to a transposition of the matrix), a permutation of these numbers results , which by





for and can be specified. The number of deficiencies and thus also the sign of can be explicitly passed through


-
 and
and 
determine. In number theory , for example, in Zolotareff's lemma , these permutations are used to prove the quadratic reciprocity law .
Generalizations
In a more general way, matrices with entries from a ring (possibly with one ) can also be considered, whereby a large part of the properties of transposed matrices is retained. In arbitrary rings, however, the column rank of a matrix does not have to match its row rank. The product formula and the representation of determinants are only valid in commutative rings .
See also
literature
-
Siegfried Bosch : Linear Algebra . Springer, 2006, ISBN 3-540-29884-3 .
-
Gerd Fischer : Linear Algebra: An Introduction for New Students . Springer, 2008, ISBN 3-8348-9574-1 .
- Roger Horn, Charles R. Johnson: Matrix Analysis . Cambridge University Press, 1990, ISBN 978-0-521-38632-6 .
- Eberhard Oeljeklaus, Reinhold Remmert: Linear Algebra I . Springer, 2013, ISBN 978-3-642-65851-8 .
Original work
-
Arthur Cayley : A memoir on the theory of matrices . In: Philosophical Transactions of the Royal Society of London . tape 148 , 1858, pp. 17-37 ( online ).
Individual evidence
-
^ Christian Voigt, Jürgen Adamy: Collection of formulas for the matrix calculation . Oldenbourg Verlag, 2007, p. 9 .
-
↑ Eberhard Oeljeklaus, Reinhold Remmert: Linear Algebra I . Springer, 2013, p. 153 .
-
^ O. Taussky, H. Zassenhaus: On the similarity transformation of matrix and its transpose . In: Pacific J. Math. Band 9 , 1959, pp. 893-896 .
-
^ Franz Lemmermeyer: Reciprocity Laws: From Euler to Eisenstein . Springer, 2000, p. 32 .
Web links





