
This
scatter diagram shows a concrete empirical regression line of a linear single regression, which was placed as
best as possible through the "point cloud" of the measurement.
In statistics , the linear single regression , or also simple linear regression (short: ELR , rarely univariate linear regression ) is a regression analysis method and a special case of linear regression . The term simple indicates that only one independent variable is used in linear single regression to explain the outcome. The aim is to estimate the axis intercept and slope of the regression line as well as to estimate the variance of the disturbance variables .
Introduction to the problem
The goal of a regression is to explain a dependent variable by one or more independent variables. In simple linear regression, a dependent variable is simply explained by an independent variable . The model of linear single regression is therefore based on two metric variables: an influencing variable (also: explanatory variable, regressor or independent variable) and a target variable (also: endogenous variable , dependent variable, declared variable or regressand). In addition, there are pairs of measured values (the representation of the measured values in the - diagram is referred to in the following as a scatter diagram ) which are functionally related, which is composed of a systematic and a stochastic part:







The stochastic component describes only random influences (e.g. random deviations such as measurement errors ); all systematic influences are contained in the systematic component. The linear single regression establishes the connection between the influence and the target variable with the help of two fixed, unknown, real parameters and in a linear way, i.e. H. the regression function is specified as follows :



-
 ( Linearity )
( Linearity )
This results in the model of simple linear regression as follows: . Here is the dependent variable and represents a random variable . The values are observable, non-random measured values of the known explanatory variables ; the parameters and are unknown scalar regression parameters and is a random and unobservable disturbance variable. In simple linear regression, a straight line is drawn through the scatter plot in such a way that the linear relationship between and is described as well as possible.




Introductory example
A well-known sparkling wine producer wants to bring a high-quality Riesling sparkling wine to market. To determine the sales price , a price-sales function should first be determined. For this purpose, a test sale is carried out in shops and you get six value pairs with the respective retail price of a bottle (in euros) and the number of bottles sold :

business 
|
1
|
2
|
3
|
4th
|
5
|
6th
|
|
Bottle price
|
20th
|
16
|
15th
|
16
|
13
|
10
|
sold amount 
|
0
|
3
|
7th
|
4th
|
6th
|
10
|
If one looks at the above scatter diagram, one can assume that there is a linear relationship. There you can see that the entered data points are almost on a line. Furthermore, the price is defined as an independent variable and the number of bottles sold as a dependent variable and there are six observations. The number of bottles sold may not only depend on the price, e.g. B. could have hung a large billboard in the sales point 3, so that more bottles were sold there than expected (coincidental influence). So the simple linear regression model seems to fit.
After the graphical inspection of whether there is a linear relationship, the regression line is first estimated using the least squares method and the formulas in the info box for the estimated regression parameters result .
A result of the following numerical example for the dependent and independent variables each mean to and . Thus, the estimated values for and for are obtained by simply inserting them into the formulas explained below. Intermediate values (e.g. ) in these formulas are shown in the following table






|
Bottle price 
|
sold amount 
|

|

|

|

|

|

|

|

|
| 1
|
20th
|
0
|
5
|
−5
|
−25
|
25th
|
25th
|
0.09
|
−0.09
|
0.0081
|
| 2
|
16
|
3
|
1
|
−2
|
−2
|
1
|
4th
|
4.02
|
−1.02
|
1.0404
|
| 3
|
15th
|
7th
|
0
|
2
|
0
|
0
|
4th
|
5.00
|
2.00
|
4.0000
|
| 4th
|
16
|
4th
|
1
|
−1
|
−1
|
1
|
1
|
4.02
|
−0.02
|
0.0004
|
| 5
|
13
|
6th
|
−2
|
1
|
−2
|
4th
|
1
|
6.96
|
−0.96
|
0.9216
|
| 6th
|
10
|
10
|
−5
|
5
|
−25
|
25th
|
25th
|
9.91
|
0.09
|
0.0081
|
|
total
|
90
|
30th
|
0
|
0
|
−55
|
56
|
60
|
30.00
|
0.00
|
5.9786
|
It results in the example
-
 and .
and .
The estimated regression line is thus
-
 ,
,
so that one can assume that for every euro more, sales decrease by about one bottle on average.
The sales volume can be calculated for a specific price , e.g. B. results in an estimated sales volume of . An estimated sales volume can be specified for each observation value, e.g. B. for results . The estimated disturbance variable, called the residual , is then .





Coefficient of determination

Scatter plot of residuals with no structure that yields

The coefficient of determination measures how well the measured values to a regression model fit ( goodness ). It is defined as the proportion of the " explained variation " in the " total variation " and is therefore between:

-
 (or ): no linear relationship and
(or ): no linear relationship and
-
 (or ): perfect linear relationship.
(or ): perfect linear relationship.
The closer the coefficient of determination is to the value one, the higher the “specificity” or “quality” of the adjustment. Is , then the “best” linear regression model consists only of the intercept while is. The closer the value of the coefficient of determination is, the better the regression line explains the true model . If , then the dependent variable can be fully explained by the linear regression model. The measurement points then clearly lie on the non-horizontal regression line. In this case, there is no stochastic relationship, but a deterministic one.



A common misinterpretation of a low coefficient of determination is that there is no connection between the variables. In fact, only the linear relationship is measured, i.e. H. although is small, there can still be a strong nonlinear relationship. Conversely, a high value of the coefficient of determination does not have to mean that a nonlinear regression model is not even better than a linear model.

In a simple linear regression, the coefficient of determination corresponds to the square of the Bravais-Pearson correlation coefficient (see coefficient of determination as a squared correlation coefficient ).

In the above example, the quality of the regression model can be checked with the aid of the coefficient of determination . For the example we get the residual sum of squares and the total sum of squares
-
 and
and 
and the coefficient of determination
-
 .
.
This means that approx. 90% of the variation or scatter in can be "explained" with the help of the regression model, only 10% of the scatter remains "unexplained".
The model

Data set with true regression line (blue) and estimated regression line (red) as well as true disturbance variable and estimated disturbance variable (residual).
In the regression model, the random components are modeled with the help of random variables . If is a random variable, then it is too . The observed values are interpreted as realizations of the random variables .
This results in the simple linear regression model:
-
 (with random variables ) or
(with random variables ) or
-
 (with their realizations).
(with their realizations).
Figuratively speaking, a straight line is drawn through the scatter plot of the measurement. In the current literature, the straight line is often described by the axis intercept and the slope parameter. The dependent variable is often called the endogenous variable in this context. There is an additive stochastic disturbance variable that measures deviations from the ideal relationship - i.e. the straight line - parallel to the axes.
The regression parameters and are estimated on the basis of the measured values . This is how the sample regression function is obtained . In contrast to the independent and dependent variables, the random components and their realizations are not directly observable. Their estimated realizations are only indirectly observable and are called residuals . They are calculated quantities and measure the vertical distance between the observation point and the estimated regression line 

Model assumptions
In order to ensure the decomposition of into a systematic and random component and to have good estimation properties for the estimation and the regression parameters and , some assumptions regarding the disturbance variables and the independent variable are necessary.
Assumptions about the independent variable
With regard to the independent variable, the following assumptions are made:
- The values of the independent variables are deterministic, ie they are fixed
- They can therefore be controlled like in an experiment and are therefore not random variables ( exogeneity of the regressors ). If the random variables, e.g. B. if they can only be measured with errors, then the distribution of and the distribution parameters ( expected value and variance) would not only depend on

-
 .
.
- This case can also be treated with special regression methods, see e.g. B. Regression with stochastic regressors .
- Sample variation in the independent variable
- The realizations of the independent variables are not all the same. So one rules out the unlikely case that the independent variable shows no variability; H. . This implies that the sum of squares of the independent variable must be positive. This assumption is required in the estimation process.



Assumptions about the independent and dependent variable
- The true relationship between the variables and is linear
- The regression equation of simple linear regression must be linear in the parameters and , but can include nonlinear transformations of the independent and dependent variables. For example the transformations
-
 and
and 
permissible because they also represent linear models . Note that transformed data changes the interpretation of the regression parameters.
- Presence of a random sample
There is a random sample of the scope with realizations that follows the true model .


Assumptions about the disturbance variables
The following assumptions are made with regard to the disturbance variables:
- The expected value of the disturbance variables is zero:
- If the model contains an axis intercept that differs from zero, it is reasonable to require at least that the mean value of in the population is zero and that the fluctuations of the individual disturbance variables balance out over the entirety of the observations. Mathematically, this means that the expected value of the disturbance variables is zero . This assumption does not make a statement about the relationship between and , but only makes a statement about the distribution of the unsystematic component in the population. This means that the model under consideration corresponds on average to the true relationship. If the expected value were not zero, then on average one would estimate a wrong relationship. This assumption can be violated if a relevant variable is not taken into account in the regression model (see bias due to omitted variables ).


- The disturbance variables are mutually independent random variables

- If the disturbance variables were not independent, one could formulate a systematic relationship between them. That would contradict breaking down into a clear systematic and random component. In the time series analysis, e.g. B. is often considered a connection of form .

- Often only the uncorrelatedness of the disturbance variables is required: or equivalent .
![{\ displaystyle \ operatorname {Cov} (\ varepsilon _ {i}, \ varepsilon _ {j}) = \ operatorname {E} [(\ varepsilon _ {i} - \ operatorname {E} (\ varepsilon _ {i}) )) ((\ varepsilon _ {j} - \ operatorname {E} (\ varepsilon _ {j}))] = \ operatorname {E} (\ varepsilon _ {i} \ varepsilon _ {j}) = 0 \ quad \ forall i \ neq j, \; i = 1, \ ldots, n, \; j = 1, \ ldots, n}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f7c55c63cc247f0e6ee0b6a1b2aab78176723913)

Independent random variables are always also uncorrelated. In this context, one speaks of the absence of autocorrelation .
- A constant variance ( homoscedasticity ) of the disturbance variables:

- If the variance were not constant, the variance could possibly be modeled systematically, i. H. this would contradict the decomposition of into a clear systematic and random component. It can also be shown that the estimation properties of the regression parameters can be improved if the variance is not constant.
All of the above assumptions about the disturbance variables can be summarized as follows:
-
 ,
,
d. H. all disturbance variables are independent and identically distributed with expected value and .


- Optional assumption: the disturbance variables are normally distributed , i.e.

- This assumption is only needed to e.g. B. to calculate confidence intervals or to perform tests for the regression parameters.
If the normal distribution of the disturbance variables is assumed, it follows that the following is also normal:

The distribution of the depends on the distribution of the disturbance variables. The expected value of the dependent variable is:

Since the only random component in the disturbance is the variance of the dependent variable, it is equal to the variance of the disturbance:
-
 .
.
The variance of the disturbance variables thus reflects the variability of the dependent variables around their mean value. This results in the distribution of the dependent variables:
-
 .
.
Based on the assumption that the disturbance variables must be zero on average, the expected value of the regression function of the population must be

correspond. I.e. with the assumption about the disturbance variables one concludes that the model has to be correct on average. If, in addition to the other assumptions, the assumption of normal distribution is also required, one also speaks of the classical linear model (see also #Classical linear model of normal regression ).
As part of the regression diagnosis , the requirements of the regression model should be checked as far as possible. This includes checking whether the disturbance variables have no structure (which would then not be random).
Estimation of the regression parameters and the confounding variables
The estimation of the regression parameters and the disturbance variables takes place in two steps:
- First of all, the unknown regression parameters and are estimated with the help of least squares estimation . The sum of the squared deviations between the estimated regression value and the observed value is minimized. The following formulas result:



- If and are calculated, the residual can be estimated as .

Derivation of the formulas for the regression parameters

Least Squares Method: The sum of the blue squares of differences is the
total sum of squares and the sum of the red
squares is the sum of squares of residuals . The least squares estimates and minimize the sum of the squares of the perpendicular distances of the data points from the regression line.


In order to determine the parameters of the straight line, the objective function ( sum of squares of errors or the sum of squares of residuals ) is minimized


The first order conditions ( necessary conditions ) are:

and
-
 .
.
By setting the partial derivatives according to and to zero, the parameter estimates we are looking for are obtained , for which the sum of the squares of the residuals is minimal:
-
 and ,
and ,
wherein the sum of differential products between and and the sum of squares of representing. With the aid of Steiner's theorem of displacement , the following can also be represented more simply, in a non- centered form


-
 .
.
Further representations of can be obtained by writing the formula as a function of the Bravais-Pearson correlation coefficient . Either as
-
 or ,
or ,
where and represent the empirical standard deviations of and . The latter representation implies that the least squares estimator for the slope is proportional to the Bravais-Pearson correlation coefficient , ie .



The respective least squares estimates of and are abbreviated as and .
Algebraic Properties of Least Squares Estimators
Three properties can be derived from the formulas:
1.) The regression line runs through the center of gravity or through the "center of gravity" of the data , which follows directly from the definition of above . It should be noted that this only applies if an intercept is used for the regression, as can easily be seen in the example with the two data points .


2.) The KQ regression line is determined in such a way that the residual sum of squares becomes a minimum. Equivalently, this means that positive and negative deviations from the regression line cancel each other out. If the model of linear single regression contains an intercept that differs from zero, then it must be true that the sum of the residuals is zero (this is equivalent to the property that the averaged residuals result in zero)
-
 or .
or .
- Or, as the residuals as a function of interference can be displayed . This representation is required for the derivation of the unbiased estimate of the variance of the disturbance variables .

3.) The residuals and the independent variables are (regardless of whether an axis intercept was included or not) uncorrelated, i. H.
-
 , which follows directly from the second optimality condition above.
, which follows directly from the second optimality condition above.
- The residuals and the estimated values are uncorrelated; H.
-
 .
.
- This uncorrelation of the predicted values with the residuals can be interpreted in such a way that all relevant information of the explanatory variables with regard to the dependent variables is already contained in the prediction.
Estimator functions of the least squares estimator
The estimation functions for and for can be derived from the regression equation.
-
 with the weight function
with the weight function 
-
 .
.
The formulas also show that the estimators of the regression parameters depend linearly on. Assuming a normal distribution of the residuals (or if, for the central limit theorem is satisfied), it follows that also the estimation functions of the regression parameters , and are at least approximate a normal distribution:

-
 and .
and .
Statistical Properties of Least Squares Estimators
Unexpected least squares estimator
The estimators of the regression parameters and are fair to expectation for and , i.e. H. it applies and . The least squares estimator therefore delivers the true values of the coefficients “on average” .


By linearity of expectation and requirement follows namely and: . The expected value of is therefore:



For the expected value of we finally get:
-
 .
.
Variances of the Least Squares Estimator
The variances of the intercept and the slope parameter are given by:
-
 and
and
-
![{\ displaystyle {\ begin {aligned} \; \ sigma _ {{\ hat {\ beta}} _ {1}} ^ {2} = \ operatorname {Var} ({\ hat {\ beta}} _ {1 }) & = \ operatorname {Var} \ left ({\ frac {\ sum \ nolimits _ {i = 1} ^ {n} (x_ {i} - {\ overline {x}}) (Y_ {i} - {\ overline {Y}})} {\ sum \ nolimits _ {i = 1} ^ {n} \ left (x_ {i} - {\ overline {x}} \ right) ^ {2}}} \ right ) = \ operatorname {Var} \ left ({\ frac {\ sum \ nolimits _ {i = 1} ^ {n} (x_ {i} - {\ overline {x}}) Y_ {i}} {\ sum \ nolimits _ {i = 1} ^ {n} \ left (x_ {i} - {\ overline {x}} \ right) ^ {2}}} \ right) \\ & \\ & = {\ frac { \ sum \ nolimits _ {i = 1} ^ {n} (x_ {i} - {\ overline {x}}) ^ {2} \ operatorname {Var} (Y_ {i})} {\ left [\ sum \ nolimits _ {i = 1} ^ {n} \ left (x_ {i} - {\ overline {x}} \ right) ^ {2} \ right] ^ {2}}} = \ sigma ^ {2} \ underbrace {\ frac {1} {\ sum \ nolimits _ {i = 1} ^ {n} (x_ {i} - {\ overline {x}}) ^ {2}}} _ {=: a_ {1 }} = \ sigma ^ {2} \ cdot a_ {1} \ end {aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1696de07d38947b2191c78ec72de63c97156552f) .
.
It turns the empirical variance . The larger the dispersion in the explanatory variables (i. E. The greater the precision is), the greater of and . Because the larger the sample size , the greater the number of terms in the expression , larger samples always result in greater precision. It can also be seen that the smaller the variance of the disturbance variables , the more precise the estimators are.


The covariance of and is given by
-
 .
.
If for the consistency condition


holds, are the least squares estimators and are consistent for and . This means that as the sample size increases, the true value is estimated more accurately and the variance ultimately disappears. The consistency condition means that the values vary sufficiently around their arithmetic mean. This is the only way to add additional information to the estimation of and . The problem with the two variance formulas, however, is that the true variance of the confounding variables is unknown and must therefore be estimated. The positive square roots of the estimated variances are known as the (estimated) standard errors of the regression coefficients and and are important for assessing the goodness of fit (see also standard errors of the regression parameters in the simple regression model ).

Estimator for the variance of the disturbance variables
An unbiased estimate of the variance of the disturbance variables is given by
-
 ,
,
d. i.e., it holds (for a proof, see unbiased estimators for the variance of the disturbance variables ). The positive square root of this unbiased estimator is also known as the standard error of regression . The estimate of is also called the mean residual square . The mean residual square is needed to determine confidence intervals for and .



Replacing with in the above formulas for the variances of the regression parameters provides the estimates and for the variances.


Best linear unbiased estimator
It can be shown that the least squares estimator is the best linear unbiased estimator. One unbiased estimator is “better” than another if it has a smaller variance, since the variance is a measure of the uncertainty. The best estimator is thus characterized by the fact that it has a minimal variance and thus the lowest uncertainty. That estimation function, which has the smallest variance among the linear unbiased estimators is, as best linear unbiased estimator , short BLES ( English Best Linear Unbiased Estimator , in short: BLUE ), respectively. For all other linear unbiased estimators and therefore applies


-
 and .
and .
Even without assuming normal distribution, the least squares estimator is the best linear unbiased estimator.
Classic linear model of normal regression
If, in addition to the classical assumptions, one assumes that the disturbance variables are normally distributed ( ), then it is possible to carry out statistical inference (estimation and testing). A model that also fulfills the assumption of normal distribution is called the classical linear model of normal regression . With such a model, confidence intervals and tests can then be constructed for the regression parameters. In particular, this normal distribution assumption is required for t -test, since a t -distribution is used as the test variable distribution , which is obtained by dividing a standard normally distributed random variable by the square root of a chi-square distributed random variable (corrected for the number of its degrees of freedom).
t tests
The assumption of normal distribution implies and thus results in the following t statistic for axis intercept and slope :


-
 .
.
For example, a significance test can be carried out in which the null hypothesis and alternative hypothesis are specified as follows : against . The following then applies to the test variable:


-
 ,
,
where is that of the t distribution with degrees of freedom.



Confidence intervals
In order to derive confidence intervals for the case of linear single regression, one needs the normal distribution assumption for the disturbance variables. As a confidence interval for the unknown parameters and one obtains:

-
![{\ displaystyle KI_ {1- \ alpha} (\ beta _ {0}) = \ left [{\ hat {\ beta}} _ {0} - {\ hat {\ sigma}} _ {{\ hat {\ beta}} _ {0}} t_ {1- \ alpha / 2} (n-2); {\ hat {\ beta}} _ {0} + {\ hat {\ sigma}} _ {{\ hat { \ beta}} _ {0}} t_ {1- \ alpha / 2} (n-2) \ right] \;}](https://wikimedia.org/api/rest_v1/media/math/render/svg/40fb9761008e28d654d5917e4cfe5e7fe04481a4) and ,
and ,![{\ displaystyle \; KI_ {1- \ alpha} (\ beta _ {1}) = \ left [{\ hat {\ beta}} _ {1} - {\ hat {\ sigma}} _ {{\ has {\ beta}} _ {1}} t_ {1- \ alpha / 2} (n-2); {\ hat {\ beta}} _ {1} + {\ hat {\ sigma}} _ {{\ has {\ beta}} _ {1}} t_ {1- \ alpha / 2} (n-2) \ right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/49486277a6713c00ad492c5573dee76cefb77ab0)
where the - is the quantile of the Student's t distribution with degrees of freedom and the estimated standard errors and the unknown parameters and are given by the square roots of the estimated variances of the least squares estimators :




-
 and ,
and ,
where represents the mean residual square .
forecast
Often one is interested in estimating the (realization) of the dependent variable for a new value . For example, it could be the planned price of a product and its sales. In this case the same simple regression model is assumed as shown above. For a new observation with the value of the independent variable , the prediction based on simple linear regression is given by



Since one can never exactly predict the value of the dependent variable, there is always an estimation error. This error is called the prediction error and results from

In the case of simple linear regression, the expected value and the variance of the prediction error result:
-
 and .
and .
In the case of point predictions, specifying a prediction interval is used to express the prediction precision and reliability. With probability , the variable will take on a value at that point , which lies in the following -prediction interval
-
 .
.
This form of the confidence interval shows immediately that the confidence interval becomes wider as the independent prediction variable moves away from the “center of gravity” of the data. Estimates of the dependent variables should therefore be within the observation space of the data, otherwise they will be very unreliable.
Causality and direction of regression
As repeatedly emphasized in the statistical literature, a high value of is the correlation coefficient between two variables and alone is not sufficient evidence of the causal (d. H. Causal) link between and , nor for its possible direction. A fallacy of the kind cum hoc ergo propter hoc is possible here.
Other than as described generally, one should therefore in the linear regression of two variables , and always have to do with not just one but two independent regression line: the first for the assumed linear relationship (regression of on ), the second for no less possible dependency (regression of on ).


If the direction of the -axis is referred to as horizontal and that of the -axis as vertical, the calculation of the regression parameter amounts to the usually determined minimum of the vertical squared deviations in the first case , in contrast to the minimum of the horizontal squared deviations in the second case .
From a purely external point of view, the two regression lines and a pair of scissors form the intersection and pivot point of which is the focus of the data . The wider this gap opens, the lower the correlation between the two variables, right up to the orthogonality of both regression lines, expressed numerically by the correlation coefficient or angle of intersection .


Conversely, the correlation between the two variables increases the more the gap closes - with collinearity of the direction vectors of both regression lines, finally, i.e. when both are visually superimposed, the maximum value or assumes, depending on the sign of the covariance , which means that between and there is a strictly linear relationship and (mind you, only in this single case) the calculation of a second regression line is unnecessary.


As can be seen in the following table, the equations of the two regression lines have great formal similarity, for example in terms of their increases or , respectively, which are equal to the respective regression parameters and differ only in their denominators: in the first case the variance of , in the second the from :


| Regression from on
|
Measures of connection
|
Regression from on
|
Regression coefficient
|
Product-moment correlation
|
Regression coefficient
|

|

|

|
| Empirical regression coefficient
|
Empirical correlation coefficient
|
Empirical regression coefficient
|

|

|

|
| Regression line
|
Coefficient of determination
|
Regression line
|

|

|

|
The mathematical mean position of the correlation coefficient and its square, the coefficient of determination, compared to the two regression parameters can also be seen, resulting from the fact that instead of the variances of or their geometric mean

in the denominator. If one considers the differences as components of a -dimensional vector and the differences as components of a -dimensional vector , the empirical correlation coefficient can finally also be interpreted as the cosine of the angle enclosed by both vectors :






example
For the previous example from the sparkling wine cellar, the following table results for the regression from to
and for the regression from to :
|
|
Bottle price
|
sold amount
|
|
|
|
|
|
|

|
| 1
|
20th
|
0
|
5
|
−5
|
−25
|
25th
|
25th
|
0.09
|
19.58
|
| 2
|
16
|
3
|
1
|
−2
|
−2
|
1
|
4th
|
4.02
|
16.83
|
| 3
|
15th
|
7th
|
0
|
2
|
0
|
0
|
4th
|
5.00
|
13.17
|
| 4th
|
16
|
4th
|
1
|
−1
|
−1
|
1
|
1
|
4.02
|
15.92
|
| 5
|
13
|
6th
|
−2
|
1
|
−2
|
4th
|
1
|
6.96
|
14.08
|
| 6th
|
10
|
10
|
−5
|
5
|
−25
|
25th
|
25th
|
9.91
|
10.42
|
|
total
|
90
|
30th
|
0
|
0
|
−55
|
56
|
60
|
30.00
|
90.00
|
This results in the following values for the regression from to :
|
|
Regression from on
|
| coefficient
|
General formula
|
Value in the example
|
| Slope parameter of the regression line
|

|

|
| Intercept of the regression line
|

|

|
| Estimated regression line
|

|

|
And the values for the regression from to are:
|
|
Regression from on
|
| coefficient
|
General formula
|
Value in the example
|
| Slope parameter of the regression line
|

|

|
| Intercept of the regression line
|

|

|
| Estimated regression line
|

|

|
That means, depending on whether you are performing the regression from on or the regression from on , you get different regression parameters. For the calculation of the correlation coefficient and the coefficient of determination, however, the regression direction does not play a role.
|
Empirical Correlation
|

|

|
|
Coefficient of determination
|

|

|
Single linear regression through the origin
In the case of simple linear regression through the origin / regression without an axis intercept (the axis intercept is not included in the regression and therefore the regression equation runs through the coordinate origin ) the concrete empirical regression line is , where the notation is used to derive from the general problem of estimating a To distinguish slope parameters with the addition of an axis intercept. Sometimes it is appropriate to put the regression line through the origin when and are assumed to be proportional. Least squares estimation can also be used in this special case. It provides for the slope


-
 .
.
This estimator for the slope parameter corresponds to the estimator for the slope parameter if and only if . If true intercept is true, then is a biased estimate of the true slope parameter . Another coefficient of determination must be defined for the linear single regression through the origin, since the usual coefficient of determination can become negative in the case of a regression through the origin (see coefficient of determination # Simple linear regression through the origin ). The variance of is given by


-
 .
.
This variance becomes minimal when the sum in the denominator is maximal.
Matrix notation
The model character of the simple linear regression model becomes particularly clear in the matrix notation with the data matrix :
-
 ( true model ).
( true model ).
With

This representation makes it easier to generalize to several influencing variables (multiple linear regression).
Relationship to multiple linear regression
Single linear regression is a special case of multiple linear regression . The multiple linear regression model
-
 ,
,
represents a generalization of the linear single regression with regard to the number of regressors. Here, the number of regression parameters is. For , the linear single regression results.


Linear single regression in R
As a simple example, the correlation coefficient of two data series is calculated:
# Groesse wird als numerischer Vektor
# durch den Zuweisungsoperator "<-" definiert:
Groesse <- c(176, 166, 172, 184, 179, 170, 176)
# Gewicht wird als numerischer Vektor definiert:
Gewicht <- c(65, 55, 67, 82, 75, 65, 75)
# Berechnung des Korrelationskoeffizienten nach Pearson mit der Funktion "cor":
cor(Gewicht, Groesse, method = "pearson")
The result is 0.9295038.
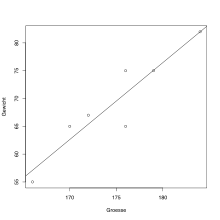
Graphic output of the example
A linear single regression can be carried out using the statistical software R. This can be done in R by the function lm , where the dependent variable is separated from the independent variables by the tilde. The summary function outputs the coefficients of the regression and other statistics:
# Lineare Regression mit Gewicht als Zielvariable
# Ergebnis wird als reg gespeichert:
reg <- lm(Gewicht~Groesse)
# Ausgabe der Ergebnisse der obigen linearen Regression:
summary(reg)
Diagrams are easy to create:
# Streudiagramm der Daten:
plot(Gewicht~Groesse)
# Regressionsgerade hinzufügen:
abline(reg)
Web links
literature
- George G. Judge, R. Carter Hill, W. Griffiths, Helmut Lütkepohl , TC Lee. Introduction to the Theory and Practice of Econometrics. John Wiley & Sons, New York, Chichester, Brisbane, Toronto, Singapore, ISBN 978-0471624141 , second edition 1988.
- Norman R. Draper, Harry Smith: Applied Regression Analysis. Wiley, New York 1998.
-
Ludwig von Auer : Econometrics. An introduction. Springer, ISBN 978-3-642-40209-8 , 6th through. u. updated edition 2013
-
Ludwig Fahrmeir , Thomas Kneib , Stefan Lang, Brian Marx: Regression: models, methods and applications. Springer Science & Business Media, 2013, ISBN 978-3-642-34332-2
- Peter Schönfeld: Methods of Econometrics . Berlin / Frankfurt 1969.
- Dieter Urban, Jochen Mayerl: Regression analysis: theory, technology and application. 2., revised. Edition. VS Verlag, Wiesbaden 2006, ISBN 3-531-33739-4 .
Individual evidence
-
^ W. Zucchini, A. Schlegel, O. Nenadíc, S. Sperlich: Statistics for Bachelor and Master students.
-
^ A b Ludwig von Auer : Econometrics. An introduction. Springer, ISBN 978-3-642-40209-8 , 6th, through. u. updated edition. 2013, p. 49.
-
↑ a b Jeffrey Marc Wooldridge : Introductory econometrics: A modern approach. 5th edition. Nelson Education 2015, p. 59.
-
^ Karl Mosler and Friedrich Schmid: Probability calculation and conclusive statistics. Springer-Verlag, 2011, p. 292.
-
↑ Jeffrey Marc Wooldridge: Introductory econometrics: A modern approach. 5th edition. Nelson Education 2015, p. 24.
-
↑ a b Jeffrey Wooldridge: Introductory Econometrics: A Modern Approach . 5th international edition. South-Western, Mason, OH 2013, ISBN 978-1-111-53439-4 , pp. 113-114 (English).
-
↑ JF Kenney, ES Keeping: Linear Regression and Correlation. In: Mathematics of Statistics. Pt. 1, 3rd edition. Van Nostrand, Princeton, NJ 1962, pp. 252-285.
-
^ Rainer Schlittgen : Regression analyzes with R. 2013, ISBN 978-3-486-73967-1 , p. 4 (accessed via De Gruyter Online).
-
Analogous to ( argument of the maximum ), ↑ denotes the argument of the minimum


-
↑ Manfred Precht and Roland Kraft: Bio-Statistics 2: Hypothesis tests – analysis of variance – non-parametric statistics – analysis of contingency tables – correlation analysis – regression analysis – time series analysis – program examples in MINITAB, STATA, N, StatXact and TESTIMATE : 5., completely revised. Edition Reprint 2015, De Gruyter, Berlin June 2015, ISBN 978-3-486-78352-0 (accessed from De Gruyter Online), p. 299.
-
^ Rainer Schlittgen: Regression analyzes with R. 2013, ISBN 978-3-486-73967-1 , p. 27 (accessed via De Gruyter Online).
-
↑ Werner Timischl : Applied Statistics. An introduction for biologists and medical professionals. 2013, 3rd edition, p. 326.
-
↑ Werner Timischl: Applied Statistics. An introduction for biologists and medical professionals. 2013, 3rd edition, p. 326.
-
↑ George G. Judge, R. Carter Hill, W. Griffiths, Helmut Lütkepohl , TC Lee. Introduction to the Theory and Practice of Econometrics. 2nd Edition. John Wiley & Sons, New York / Chichester / Brisbane / Toronto / Singapore 1988, ISBN 0-471-62414-4 , p. 168.
-
^ Ludwig Fahrmeir , Rita artist, Iris Pigeot , Gerhard Tutz : Statistics. The way to data analysis. 8., revised. and additional edition. Springer Spectrum, Berlin / Heidelberg 2016, ISBN 978-3-662-50371-3 , p. 443.
-
↑ Jeffrey Marc Wooldridge: Introductory econometrics: A modern approach. 5th edition. Nelson Education 2015
-
^ Karl Mosler and Friedrich Schmid: Probability calculation and conclusive statistics. Springer-Verlag, 2011, p. 308.
-
↑ Werner Timischl : Applied Statistics. An introduction for biologists and medical professionals. 2013, 3rd edition, p. 313.
-
^ Rainer Schlittgen: Regression analyzes with R. 2013, ISBN 978-3-486-73967-1 , p. 13 (accessed via De Gruyter Online).
-
↑ Ludwig von Auer : Econometrics. An introduction. Springer, ISBN 978-3-642-40209-8 , 6th, through. u. updated edition. 2013, p. 135.
-
^ Walter Gellert, Herbert Küstner, Manfred Hellwich, Herbert Kästner (Eds.): Small encyclopedia of mathematics. Leipzig 1970, pp. 669-670.
-
↑ Jeffrey Marc Wooldridge: Introductory econometrics: A modern approach. 4th edition. Nelson Education, 2015, p. 57.
-
↑ Lothar Sachs , Jürgen Hedderich: Applied Statistics: Collection of Methods with R. 8., revised. and additional edition. Springer Spectrum, Berlin / Heidelberg 2018, ISBN 978-3-662-56657-2 , p. 801







.svg)







